you don't need a weatherman
to know which way the wind blows
The chosen few are set to announce their lists of the top tech trends that we should all be embracing or bracing for. The following isn't such a list. Mine is more of a list of things that I hope more people will pay more attention to. Which is why I wrote this list.
MY TOP TECH BENDS
1. Free as in library
Found a beautiful digitally-scanned collection of pre-1923 books; the library who scanned them claims copyright on them. WANT. TO. PUNCH.
— Jason Scott (@textfiles) January 14, 2012
If you are part of a library or other not-for-profit that takes historical material and then places that material behind a paywall or makes the works available but with copyright restrictions, be prepared to feel a little less gratitude and a little more wrath for your labour. Better have an answer ready to this question: why didn't you add the material to the Internet Archive or to Wikimedia instead?
2. More is different
Regular folk have been reading books on their e-readers for a handful of years now. How much longer will it be before these e-readers start adding new features that take fuller advantages of what digital text is capable of? I'm thinking of strange new features like Amazon's Daily Review.
I was talking with a friend last week about music and he told me a story about how he uses his iPad for his collection of music scores. Not only does it store and makes available all this music collection, the software act as a metronome, can transcribe a score into a different key, offer hands-free page turning, and even play the score so you can know what the piece is supposed to sound like. Paper scores no longer sound so wonderful to me.
3. Make Everything Digital
If you are reading this blog post then you are probably old and if you are old then you probably have much of your own work and past reading material written in ink, embedded in paper, and sitting on shelves. The amount of effort required for the digitizing of your artifacts is probably too daunting to consider seriously. But if you were starting your scholarly career all over again, would you take the time to make just one corpus of material and make everything digital? When scanning a document more often than not requires a camera or even just a camera phone, why wouldn't you?
Academic library systems are able to acquire and make available access to a large number of ebooks - largely because they have accepted many of the publishers' conditional terms for access: DRM, pdf format, and very strict downloading and printing limits. With these restrictions in place, scholars can read works but are not able to copy significant amounts of text for analysis or to manipulate the texts digitally. This raises the question: how soon will it be before we will regularly see scholars scanning their screens with their iPhones in order to make a copy of text?
4. Adding a layer over the web
Discovery layers are a cargo cult for library administrators: build something that looks like Google (but is not Google) and the good times will return as our communities will leave the internet for the promised land of the library website. At my place of work, the use of Web of Science is an order of magnitude over most other databases. Why? Web of Science presents a small, understandable set of the most important journals that cover a long period of time, along with strong linking to full-text, meaningful connections between items, and adds the ability to download, sort and parse results sets. Discovery Layers do the opposite in every way.
NCSU recently presented the results of a study of How Users Search the Library from a Single Search Box and the most frequent query of their library system- encompassing more than one percent of the total number of searches - was web+of+science. Discovery Layers: qui bono?
5. The network divide
map-of-a-tweet
The image above is a map of all the metadata associated of just one tweet. The image below is a map of the connections among the Twitter users who tweeted the word THATCamp, queried on April 30, 2011:
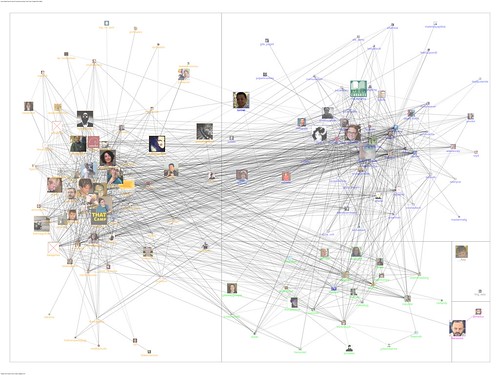
Network analysis and visualizations are of great interest and importance because what they can reveal goes far beyond what we can intuit without machines. Network analysis and visualizations requires a whole set of new competencies that I have not seen much of in libraryland, with the exception of those on Team LODLAM, who enjoyed a breakthrough season last year.
My message here is that we need to be creating data, not records, and that we need to create the data first, then build records with it for those applications where records are needed. Those records will operate internally to library systems, while the data has the potential to make connections in linked data space.
Meanwhile, librarians are still teaching Boolean logic. That's a disconnect that I'm finding difficult to ignore.
Speaking of disconnecting, I need to that now. There is much work to be done. This is what we can all agree on.







