Sunday, December 14, 2008
User Testing EVERY DAY
Meetup's Dead Simple User Testing - Boing Boing: "Obstacles to getting real feedback are now mainly cultural, not technological; any business that isn't learning from their users doesn't want to learn from their users."
Friday, December 12, 2008
Search is politics
Speaking of superheroes, please read this story by Peter Rukavina in which our hero tries to make public corporate information better searchable and more usable to the public only to have the government close off the means to such access.
Play it forward, Sam
The first time that my husband, myself and my a little-older-than newborn son went outside after coming home from the hospital, was for breakfast at The Lumberjack. Being a damn cute baby, our son got lots of attention from the few customers and wait staff that were in on that quiet Tuesday morning. Halfway through the meal, the waitress topped up our coffee cups and informed us that the two middle aged women who had just been sitting at the table next to us, had paid our bill just before leaving.
"Aw, that's sweet", I told the waitress. But as soon as she was out of earshot, my sleep-deprived reptile self hissed at Greg, "What?! Do they think we're poor?! They shouldn't give money to us! We have money! They should give their money to poor people!"
This is what came to mind as I was checking out the beta version of Akoha: "the world’s first social reality game where you can earn points by playing real-world missions with your friends". Now, I have to admit that I have a fondness for alternative reality games and so I am tempted to join into this one, especially as the cost of entry is a measly $5 (*including* shipping and handling). And, as an aspiring superhero, I want to do good in this world. But when I review the missions in the Akoha starter pack such as "Send Drinks to a Couple in Love", I just want to gag.
Like a proper game, a player must be willing to endure small pains for larger gains in the future so perhaps missions for advanced players will be more appealing. There's only one way to find out and that's to play. So I have made my decision:
I'll play if you play. Are you in?
"Aw, that's sweet", I told the waitress. But as soon as she was out of earshot, my sleep-deprived reptile self hissed at Greg, "What?! Do they think we're poor?! They shouldn't give money to us! We have money! They should give their money to poor people!"
This is what came to mind as I was checking out the beta version of Akoha: "the world’s first social reality game where you can earn points by playing real-world missions with your friends". Now, I have to admit that I have a fondness for alternative reality games and so I am tempted to join into this one, especially as the cost of entry is a measly $5 (*including* shipping and handling). And, as an aspiring superhero, I want to do good in this world. But when I review the missions in the Akoha starter pack such as "Send Drinks to a Couple in Love", I just want to gag.
Like a proper game, a player must be willing to endure small pains for larger gains in the future so perhaps missions for advanced players will be more appealing. There's only one way to find out and that's to play. So I have made my decision:
I'll play if you play. Are you in?
Monday, November 17, 2008
I am an example used in an academic paper to demonstrate that sometimes bloggers change their last names
Are Blogs Here to Stay?: An Examination of the Longevity and Currency of a Static List of Library and Information Science Weblogs
Kay Johnsona
Serials Review
Volume 34, Issue 3, September 2008, Pages 199-204
doi:10.1016/j.serrev.2008.06.009
Kay Johnsona
Serials Review
Volume 34, Issue 3, September 2008, Pages 199-204
doi:10.1016/j.serrev.2008.06.009
The titles of some of the blogs changed slightly but were still easily identified as the same blog. Authors were consistent on personal blogs, but it was difficult to determine the author or blogmaster for institutional or cooperative blogs. In the case of the “Leddy Library News,” Mita Sen-Roy originally created the site. Now, it is updated by others at Leddy Library (University of Windsor, Ontario,Canada) under a different URL. [36] I found a link to Sen-Roy’s University of Windsor Webpage and discovered her name is now Mita Williams, and she is on leave until November 2009. [37]
I will be a puppetmaster in the future
I’m chuffed!
Ok. I don't expect you to remember this, but I previously wrote about how I was playing an alternative reality game called Superstruct.
Well, one of the superstructs that I founded won The Pandora Award. This award was selected by Chris DiBona, Open Source program manager for Google for “the superstructure that is such a brilliant idea, once you hear about it, you can’t NOT do it”.
And, to boot, I am part of the SEHI 19 which wins me an invite to become a Superstruct puppetmaster next time the game is played next year.
See you in the future!
Ok. I don't expect you to remember this, but I previously wrote about how I was playing an alternative reality game called Superstruct.
Well, one of the superstructs that I founded won The Pandora Award. This award was selected by Chris DiBona, Open Source program manager for Google for “the superstructure that is such a brilliant idea, once you hear about it, you can’t NOT do it”.
And, to boot, I am part of the SEHI 19 which wins me an invite to become a Superstruct puppetmaster next time the game is played next year.
See you in the future!
Monday, November 03, 2008
Picture this - a way to improve the quality of our serial collections
This thought exercise began as I contemplated what visualizations libraries could possibly add to their websites as visualizations are all the rage now, don't you know. I was wondering if there was a logical place where it could be useful to add a sparkline or two.
So I set myself a challenge to develop a graphic that could help students decide which of our research tools would best suit their research need. So I created a graph comparing JSTOR and BioOne with an x axis of 'year' and a y axis of '# of titles'? Its pretty crude and far from a sparkline but here it is:

While this graph does convey a potentially useful snapshot comparison between these two products, I do have one major reservation with endorsing the use of such a visualization: I don't want to imply that having a higher number of titles means that one research product is better than another.
What comes to mind is the research paper "Aggregated Interdisciplinary Databases and the Needs of Undergraduate Researchers" that I think didn't get the play it deserved in the library blogosphere:
No, more is not always a better investment. But its an easy sell and sadly, librarians are unthinkinly buying into it.
Here's an alternative that came to mind. Let's apply a new limitation to our online serial collections. We can get rid of the filler out of our indexes and aggregators by setting a minimum threshold by circulation count. A library could say that they only want to pay for titles that had over 12,000 readers. And voila! Those annoying regional newsletters that clog up your search results when you are searching a business database? Gone!
Yes this is decidedly populist approach and against the recommendations by Fister et al in their paper. But consider this - such a limitation would have many additional benefits. First, it would be a strike against the Cambrian explosion of new academic titles for every microtopic and splinter school of thought. And some existing fields could stand to have fewer journal titles to improve the quality of the work of the whole. For example, according to Ulrich's there are almost 200 scholarly titles dedicated to library science published in the United States alone - and this doesn't include the open access journals that are now find online.
Secondly, a circulation statistics filter provides a useful means of selling one product (with a moveable threshold) to many libraries rather than having to create a multitude of different research products to meet the needs of all the disparate library communities in the world. In this way, online collections would mirror their print ancestors: smaller, more general educational institutions have libraries with smaller, more general publications while larger research libraries have the budgets to subscribe to many more smaller 'niche' titles.
Yes, there are obvious problems with filtering by circulation statistics and no, I am not a populist myself when it comes to my reading choices. But until someone else comes up with a reasonable alternative, the sparklines that indicate number of titles paid for but never looked at is going to go up.
So I set myself a challenge to develop a graphic that could help students decide which of our research tools would best suit their research need. So I created a graph comparing JSTOR and BioOne with an x axis of 'year' and a y axis of '# of titles'? Its pretty crude and far from a sparkline but here it is:
While this graph does convey a potentially useful snapshot comparison between these two products, I do have one major reservation with endorsing the use of such a visualization: I don't want to imply that having a higher number of titles means that one research product is better than another.
What comes to mind is the research paper "Aggregated Interdisciplinary Databases and the Needs of Undergraduate Researchers" that I think didn't get the play it deserved in the library blogosphere:
Amy Fry, Julie Gilbert and I just published an article in portal (a self-archived copy is here) that had some surprising findings about the long tail in aggregated interdisciplinary databases: looking at use of one of the market leaders at 14 largely undergraduate institutions, 4% of titles accounted for half of downloads, and these were largely popular titles; articles in 40% of full text journals were not downloaded even once at all 14 institutions. We also found that, in aggregate, the number of articles downloaded fell from 2005 to 2006 by 10%, even though the database itself was growing. Curiously, a survey of librarians show they think these growing databases are about the right size and that more full text would be an improvement. Is more always a better investment? Really? [ACRLog]
No, more is not always a better investment. But its an easy sell and sadly, librarians are unthinkinly buying into it.
Here's an alternative that came to mind. Let's apply a new limitation to our online serial collections. We can get rid of the filler out of our indexes and aggregators by setting a minimum threshold by circulation count. A library could say that they only want to pay for titles that had over 12,000 readers. And voila! Those annoying regional newsletters that clog up your search results when you are searching a business database? Gone!
Yes this is decidedly populist approach and against the recommendations by Fister et al in their paper. But consider this - such a limitation would have many additional benefits. First, it would be a strike against the Cambrian explosion of new academic titles for every microtopic and splinter school of thought. And some existing fields could stand to have fewer journal titles to improve the quality of the work of the whole. For example, according to Ulrich's there are almost 200 scholarly titles dedicated to library science published in the United States alone - and this doesn't include the open access journals that are now find online.
Secondly, a circulation statistics filter provides a useful means of selling one product (with a moveable threshold) to many libraries rather than having to create a multitude of different research products to meet the needs of all the disparate library communities in the world. In this way, online collections would mirror their print ancestors: smaller, more general educational institutions have libraries with smaller, more general publications while larger research libraries have the budgets to subscribe to many more smaller 'niche' titles.
Yes, there are obvious problems with filtering by circulation statistics and no, I am not a populist myself when it comes to my reading choices. But until someone else comes up with a reasonable alternative, the sparklines that indicate number of titles paid for but never looked at is going to go up.
Monday, September 22, 2008
Clay Shirky Talk - It's Not Information Overload. It's Filter Failure
Web 2.0 Expo NY: Clay Shirky (shirky.com) It's Not Information Overload. It's Filter Failure
There are a couple of stories in this short talk. One is the story of the student from Ryerson *University* who is charged for creating a study group on Facebook. Can we create online learning environments that support collaboration and also filter out free-riders?
There are a couple of stories in this short talk. One is the story of the student from Ryerson *University* who is charged for creating a study group on Facebook. Can we create online learning environments that support collaboration and also filter out free-riders?
Friday, September 12, 2008
A Shoutout to Liszen, Rainbows End and Superstuct
I just want to give a shout out to Liszen - the Library and Information Science Engine. I use its Firefox plugin every time I have a thought that begins with, "I wonder if anyone in the library blogosphere has written about..."
An example. I'm currently reading Vernor Vinge's Rainbows End. I'm reading it because it was mentioned by Jane McGonigal in her paper, "Why I Love Bees: A Case Study in Collective Intelligence Gaming." I'm not finished with it yet, but I can already see how it very much applies to future thinking about search & analysis and libraries. And so I thought, I wonder if anyone in the library blogosphere has written about this book?
I'm also reading the book to generate some ideas about the future world of libraries for a game I'm going to play called Superstruct. It's not so much of a game as a collective writing exercise on the future. I've played a game like this before called World Without Oil and won a one-tonne carbon offset during the game. In Superstruct, "prizes" are going to be given out by these honourary Game Masters.
There are too many of my personal heroes on this list for me to pass this opportunity up. Not that I need the possibility of egoboo to get me into this game. I really enjoyed WWO and I learned quite a bit from it, both about peak oil and how about how ad hoc communities can come together, weave their experiences around each other, and then dissolve when the street lights come on.
So not only am I reading science fiction, I'm now writing it. *Sigh* Just when I thought I couldn't get any nerdier...
If you are skeptical about the intersection between games and libraries, please consider watching this short video from The New Yorker called Saving the World Through Game Design.
An example. I'm currently reading Vernor Vinge's Rainbows End. I'm reading it because it was mentioned by Jane McGonigal in her paper, "Why I Love Bees: A Case Study in Collective Intelligence Gaming." I'm not finished with it yet, but I can already see how it very much applies to future thinking about search & analysis and libraries. And so I thought, I wonder if anyone in the library blogosphere has written about this book?
I'm also reading the book to generate some ideas about the future world of libraries for a game I'm going to play called Superstruct. It's not so much of a game as a collective writing exercise on the future. I've played a game like this before called World Without Oil and won a one-tonne carbon offset during the game. In Superstruct, "prizes" are going to be given out by these honourary Game Masters.
- Tim Kring, creator of the NBC TV series HEROES
- Warren Ellis, superhero comic book author and novelist
- Tara Hunt, social network expert and author of The Whuffie Factor
- Bruce Sterling, science fiction writer and essayist
- Jimmy Wales, founder of Wikipedia and Wikia
- Ze Frank, funniest person on the Internet
- Chris DiBona, Open Source program manager for Google
- Tim O'Reilly, founder and CEO of O'Reilly Media
- and more surprise guests to come!
There are too many of my personal heroes on this list for me to pass this opportunity up. Not that I need the possibility of egoboo to get me into this game. I really enjoyed WWO and I learned quite a bit from it, both about peak oil and how about how ad hoc communities can come together, weave their experiences around each other, and then dissolve when the street lights come on.
So not only am I reading science fiction, I'm now writing it. *Sigh* Just when I thought I couldn't get any nerdier...
If you are skeptical about the intersection between games and libraries, please consider watching this short video from The New Yorker called Saving the World Through Game Design.
Wednesday, September 10, 2008
Two things you can do for a greener library
Please add this book to your collection:

Need another endorsement to read Cradle to Cradle? Watch William McDonough's TED lecture.
Another thing you can do is encourage your library to join the movement to lend out electricity meters. I'm glad to say that my public library does this now:

Need another endorsement to read Cradle to Cradle? Watch William McDonough's TED lecture.
Another thing you can do is encourage your library to join the movement to lend out electricity meters. I'm glad to say that my public library does this now:
Saturday, August 30, 2008
The forcast is getting more cloudy all the time
Lots of different thoughts flooded my brain as I watched the introduction video to Ubiquity for Firefox. This video should be required viewing for librarians because its a proof of concept that illustrates what 'web 2.0' or 'cloud computing' can be: the user makes use of a website's services without even visiting that site.
The obvious question is how do we integrate the local library into this new ecology? I've been mulling it over and on first glance, I think that answer might be that we don't because we can't. I came to this conclusion after trying to envision a user trying to add a book or an article that they wanted to recommend to a friend. The most likely scenario is that this is an item in that user's own collection. To this end, I suspect that the most natural fit for this space is a web-based citation service such as Zotero 2.0 or newly released Mendeley. LibraryThing could work for books.
If we do want libraries to provide this service to our users (and I do), I think at a minimum, our library catalogue has to provide a means for a user to create their own virtual collections of books that include items from their library and from their own shelves . From my understanding, Bibliocommons is the only library catalogue service that can do this.
The obvious question is how do we integrate the local library into this new ecology? I've been mulling it over and on first glance, I think that answer might be that we don't because we can't. I came to this conclusion after trying to envision a user trying to add a book or an article that they wanted to recommend to a friend. The most likely scenario is that this is an item in that user's own collection. To this end, I suspect that the most natural fit for this space is a web-based citation service such as Zotero 2.0 or newly released Mendeley. LibraryThing could work for books.
If we do want libraries to provide this service to our users (and I do), I think at a minimum, our library catalogue has to provide a means for a user to create their own virtual collections of books that include items from their library and from their own shelves . From my understanding, Bibliocommons is the only library catalogue service that can do this.
Friday, August 22, 2008
On my list for next generation library catalogues - lists
One crucial feature that is missing by most library catalogues (and LibraryThing, to boot) is the ability to make and share lists of books. I consider it a crucial feature because I have this notion that most of our formal education consists of actively learning through works of text.
But there are other more subtle reasons why a listing making function is important for a library catalogue. For example, allowing users to create public lists of books is one of the few ways that readers can be connected with each other in a way that they can control.
Lists, I believe, are also an untried means by which collections librarians could share the reasons why they have selected some of their choices for the library. For example, some time ago the English Literature librarian at MPOW added We need to talk about Kevin, Vernon God Little, and Elephant (and others that I have forgotten - natch) to our collection because they were all cultural responses to the Columbine shootings. When I was collecting for science at MPOW, I actively sought out and acquired books on a number of topics (such as works about Tallgrass Prairie) that would be too narrow to properly represented in any of the traditional collection development policies. If I had the ability to create lists, I could group material together that were related but not necessarily represented by the same formalized subject heading.
Biblicommons does a fabulous job of providing users with the ability to create and share lists and does one better by automatically creating a "For later" list for each registered user. This will hopefully cut down on the inevitable "toread" tags. Although seeing a library catalogue filled with toread tags wouldn't necessarily be a sad sight to see.
But there are other more subtle reasons why a listing making function is important for a library catalogue. For example, allowing users to create public lists of books is one of the few ways that readers can be connected with each other in a way that they can control.
Lists, I believe, are also an untried means by which collections librarians could share the reasons why they have selected some of their choices for the library. For example, some time ago the English Literature librarian at MPOW added We need to talk about Kevin, Vernon God Little, and Elephant (and others that I have forgotten - natch) to our collection because they were all cultural responses to the Columbine shootings. When I was collecting for science at MPOW, I actively sought out and acquired books on a number of topics (such as works about Tallgrass Prairie) that would be too narrow to properly represented in any of the traditional collection development policies. If I had the ability to create lists, I could group material together that were related but not necessarily represented by the same formalized subject heading.
Biblicommons does a fabulous job of providing users with the ability to create and share lists and does one better by automatically creating a "For later" list for each registered user. This will hopefully cut down on the inevitable "toread" tags. Although seeing a library catalogue filled with toread tags wouldn't necessarily be a sad sight to see.
Thursday, August 21, 2008
With COinS, every library catalogue can be your library catalogue
I learned from Roy Tennant's post today that The Falvey Memorial Library at Villanova University has gone live with its VuFind library catalogue.

I tried it out and it is very nice. One feature that I especially enjoyed is that the are COinS links available so now I can add entries into Zotero and I can use their catalogue to search my catalogue.
I tried it out and it is very nice. One feature that I especially enjoyed is that the are COinS links available so now I can add entries into Zotero and I can use their catalogue to search my catalogue.
Tuesday, August 12, 2008
Because Ideas Matter - Finding Special Collections on the web
Some years ago MPOW made the painful but necessary decision to remove the bibliographies that were are all grouped together in the Reference Collection and to re-catalogue each one so that each bibliography could be found with the subject it was about. This meant that bibliographies on Shakespeare could be found with the other Shakespeare books which would make it more likely to be stumbled upon and more likely to save the user a trip to another set of stacks in the library.
I bring this up because this project came to mind when I was doing some follow up research on a book by and about Jane Jacobs. The book contains material from the Jane Jacobs Papers that are located, not in New York City or Toronto as one would first presume, but in Boston College. Now those papers are from her life from 1916 to 1995. Jane Jacobs passed away in 2006. Where are the papers from her last decade? That's not a rhetorical question - I haven't found out where they are yet.
If the future of academic libraries means currating our unique collections, we have to start doing a better job of letting the world know what we have to offer. This means recognizing that most people search for a subject - not for a bibliography or a directory of library special collections. But how can we achieve that? How can we nestle information about the unique and rich collections in our libraries right beside the subjects that they are about in the online world?
There is a way. Thank you Wikipedia.
Now you go to it! Add your library's collections to The Free Encyclopedia right now!
I bring this up because this project came to mind when I was doing some follow up research on a book by and about Jane Jacobs. The book contains material from the Jane Jacobs Papers that are located, not in New York City or Toronto as one would first presume, but in Boston College. Now those papers are from her life from 1916 to 1995. Jane Jacobs passed away in 2006. Where are the papers from her last decade? That's not a rhetorical question - I haven't found out where they are yet.
If the future of academic libraries means currating our unique collections, we have to start doing a better job of letting the world know what we have to offer. This means recognizing that most people search for a subject - not for a bibliography or a directory of library special collections. But how can we achieve that? How can we nestle information about the unique and rich collections in our libraries right beside the subjects that they are about in the online world?
There is a way. Thank you Wikipedia.
Now you go to it! Add your library's collections to The Free Encyclopedia right now!
Thursday, August 07, 2008
Good design is being mindful of the details
Today I was inspired by IDEO's Paul Bennett's TED Talk Design is in the details.
When I clicked on the video, I was expecting a showcase of stories of the design genius behind IDEO's many product successes but instead I pleasantly surprised as a Bennett described great design ideas in a hospital setting that were suggested not by his team, but by the nurses on the floor.
Bennett reminds us that good design requires mindfulness and humanity.
I was trying to think of similar instances in which the library or reading experience has been redesigned or hacked in small but significant ways and couldn't come up with any offhand.
One thing that did surface was this photo which doesn't really follow the ideas I'm pursing in this post, but does illustrate one small way in which something that is necessary and functional in a public building can also be designed to be beautiful
When I clicked on the video, I was expecting a showcase of stories of the design genius behind IDEO's many product successes but instead I pleasantly surprised as a Bennett described great design ideas in a hospital setting that were suggested not by his team, but by the nurses on the floor.
Bennett reminds us that good design requires mindfulness and humanity.
I was trying to think of similar instances in which the library or reading experience has been redesigned or hacked in small but significant ways and couldn't come up with any offhand.
One thing that did surface was this photo which doesn't really follow the ideas I'm pursing in this post, but does illustrate one small way in which something that is necessary and functional in a public building can also be designed to be beautiful
Thursday, July 31, 2008
Collaborative Story Telling as a Game
I have never played this game but I can't wait for my children to get to the age in which I can try it out with them:
The game is called Shadows and it's a very simple role playing game that even very young children can play. In Shadows, the game master is the narrator of a story. The story begins with the characters waking up somewhere from a noise. The game master will then begin a story and occasionally interrupt it to ask those who are playing to do three things: say what they want to happen next; say what "Their Shadow" - a character that always wants to get into trouble - wants to happen next; and to roll two die. If the Shadow die comes up with a higher number than the "Good" die, then the story will unfold as The Shadow wants. [LionKimbro's unalog]
I have never played role playing games myself, but my friends and I in high school and in university, used to write "add-on short stories" (otherwise known as the Surrealist game, Exquisite Corpse) via email. Looking back at them, I would say that the characters we constructed were all Shadows of our own selves.
What detractors of games in libraries may not understand (or may care not to understand as is more often the case) is that gaming can be thought of as something much larger than following a set of rules to determine a winner and a loser. I'm following the work of Jane McGonigal trying to better understand what this much larger force is and can be.
The game is called Shadows and it's a very simple role playing game that even very young children can play. In Shadows, the game master is the narrator of a story. The story begins with the characters waking up somewhere from a noise. The game master will then begin a story and occasionally interrupt it to ask those who are playing to do three things: say what they want to happen next; say what "Their Shadow" - a character that always wants to get into trouble - wants to happen next; and to roll two die. If the Shadow die comes up with a higher number than the "Good" die, then the story will unfold as The Shadow wants. [LionKimbro's unalog]
I have never played role playing games myself, but my friends and I in high school and in university, used to write "add-on short stories" (otherwise known as the Surrealist game, Exquisite Corpse) via email. Looking back at them, I would say that the characters we constructed were all Shadows of our own selves.
What detractors of games in libraries may not understand (or may care not to understand as is more often the case) is that gaming can be thought of as something much larger than following a set of rules to determine a winner and a loser. I'm following the work of Jane McGonigal trying to better understand what this much larger force is and can be.
Tuesday, July 29, 2008
Newspapers as scaffolding for local stories
When I was cobbling together my information for my last post about the current drama about my local public library system, I had to resort to sources other than my local newspaper. This is because The Windsor Star puts all its articles older than 30 days old behind a paywall. And so in order to link to background information to provided better context to what I was describing, I had to resort to these articles unofficially reprinted online elsewhere and to local blogger commentary that wasn't exactly objective.
It made me realize something. Newspapers don't just describe events that become the historical record - they provide an important structure that supports discussion of those events. Now that The New York Times has made its archive available online, users can now link to articles to provide historical context to their online writings ("I'm so GenX that I still swing it on the flippity flop").
But smaller papers haven't made this leap of faith, and so our local memory is all short term. For example, today the mayor announced a plan to build a canal and marina in downtown Windsor (link will expire in time - a related problem). My husband told me that the local CBC news also reported this story and, unlike the Windsor Star, mentioned several other instances going back into the 1980s of similar failed plans for a marina downtown. I wasn't in Windsor in the 1980s and so this local knowledge was news to me.
There's another opportunity here. With a little bit of cataloguing and perhaps some semantic linking like Harper's Magazine has done, a newspaper archive could slowly evolve into its own reference work. Maybe an arrangement could be made. Libraries could trade staff time and cataloguing expertise in exchange for making the archives available for free to the public.
There has been discussion as of late whether Google (aka The Internet) is making us stupid. Maybe that's so, but by not putting our stories about local events on the Internet, we are in danger of being perpetually ignorant.
It made me realize something. Newspapers don't just describe events that become the historical record - they provide an important structure that supports discussion of those events. Now that The New York Times has made its archive available online, users can now link to articles to provide historical context to their online writings ("I'm so GenX that I still swing it on the flippity flop").
But smaller papers haven't made this leap of faith, and so our local memory is all short term. For example, today the mayor announced a plan to build a canal and marina in downtown Windsor (link will expire in time - a related problem). My husband told me that the local CBC news also reported this story and, unlike the Windsor Star, mentioned several other instances going back into the 1980s of similar failed plans for a marina downtown. I wasn't in Windsor in the 1980s and so this local knowledge was news to me.
There's another opportunity here. With a little bit of cataloguing and perhaps some semantic linking like Harper's Magazine has done, a newspaper archive could slowly evolve into its own reference work. Maybe an arrangement could be made. Libraries could trade staff time and cataloguing expertise in exchange for making the archives available for free to the public.
There has been discussion as of late whether Google (aka The Internet) is making us stupid. Maybe that's so, but by not putting our stories about local events on the Internet, we are in danger of being perpetually ignorant.
Monday, July 28, 2008
The City Council, The Windsor Public Library Board and The CEO
The CEO of The Windsor Public Library is today's front page news after some investigative journalism has revealed that Brian Bell has been articling at a local law firm while on sick leave from his library administrative duties. According to Bell, there is no malfeasance because working at a law firm is as relaxing as pottery lessons.
The WPL has been embroiled in this sort of drama for some years now. Here's the context as I understand it.
City councils in Ontario do not have the authority to make management decisions regarding libraries because of laws designed to protect library collection decisions from political influence. The Windsor Public Library is accountable to its Library Board. And yet its safe to say that The City of Windsor have been trying to gain control of The Windsor Public Library Board. Here's the evidence:
In March of this year, Windsor City Council requested a "line by line" financial audit of the WPL despite the fact that a similar audit performed two years ago found that the library system was running efficiently. Why so many audits? "Under provincial legislation, the only way council can take over [a library board] is if there has been mismanagement, and that's the driving force behind the financial request". Also in March, Council requested that the library cut its budget by $400,000 while stipulating that there would be no reduction in hours or services. Furthermore, in May, the City tried to prematurely end the terms of the WPL Library Board members.
Complicating matters it is no secret that the mayor of Windsor and his allies in Council are not fond of Alan Halberstadt who is the only remaining city councilor on the library board. In fact, they had the knives out for him after he did not side with City Council's recommendation for such large budget cuts (addendum) and again after it was learned that the Board mistakenly applied an Pay Equity payment to "funny how the former director of Human Resources could make such a mistake" Brian Bell. As an aside, I have a tremendous respect for Alan Halberstadt and I feel that the call to remove him from the Board by some of his fellow city councillors was deeply hypocritical.
And something that might be completely irrelevant or just might be further complicating matters is that Brian Bell succeeded previous Library CEO, Steve Salmons, who may or may not be the "former librarian" referred to by local columnist Gord Henderson who is part of the Ontario government's Detroit River International Crossing team, which is, incidentally, currently battling a heated turf war with the City of Windsor's own plans for a crossing.
I'm not sure how this is all going to resolve as the WPL operates under the Carver Protocol, a commercial governance model which, according to City Councillor David Cassivi, "largely renders the library board impotent" as it vests all responsibility in the office of the library's chief executive officer.
The WPL has been embroiled in this sort of drama for some years now. Here's the context as I understand it.
City councils in Ontario do not have the authority to make management decisions regarding libraries because of laws designed to protect library collection decisions from political influence. The Windsor Public Library is accountable to its Library Board. And yet its safe to say that The City of Windsor have been trying to gain control of The Windsor Public Library Board. Here's the evidence:
In March of this year, Windsor City Council requested a "line by line" financial audit of the WPL despite the fact that a similar audit performed two years ago found that the library system was running efficiently. Why so many audits? "Under provincial legislation, the only way council can take over [a library board] is if there has been mismanagement, and that's the driving force behind the financial request". Also in March, Council requested that the library cut its budget by $400,000 while stipulating that there would be no reduction in hours or services. Furthermore, in May, the City tried to prematurely end the terms of the WPL Library Board members.
Complicating matters it is no secret that the mayor of Windsor and his allies in Council are not fond of Alan Halberstadt who is the only remaining city councilor on the library board. In fact, they had the knives out for him after he did not side with City Council's recommendation for such large budget cuts (addendum) and again after it was learned that the Board mistakenly applied an Pay Equity payment to "funny how the former director of Human Resources could make such a mistake" Brian Bell. As an aside, I have a tremendous respect for Alan Halberstadt and I feel that the call to remove him from the Board by some of his fellow city councillors was deeply hypocritical.
And something that might be completely irrelevant or just might be further complicating matters is that Brian Bell succeeded previous Library CEO, Steve Salmons, who may or may not be the "former librarian" referred to by local columnist Gord Henderson who is part of the Ontario government's Detroit River International Crossing team, which is, incidentally, currently battling a heated turf war with the City of Windsor's own plans for a crossing.
I'm not sure how this is all going to resolve as the WPL operates under the Carver Protocol, a commercial governance model which, according to City Councillor David Cassivi, "largely renders the library board impotent" as it vests all responsibility in the office of the library's chief executive officer.
Friday, July 25, 2008
Everything I Think I Know About Designing Library Websites
Summertime is usually a quiet time in an academic library – except when during the year in which it’s been deemed that the library website needs a major overhaul. Then there is a team of library staff frantically hacking away as the September deadline lurches closer and closer.
I have been involved in such three library web redesign projects at MPOW over the years and have been meaning to write down some of the things that I think I have learned from the work before it becomes irrelevant. I want to qualify these statements as things I think I know because I can’t back up these statements with proper user testing. I am a huge advocate of re-iterative user testing but that’s not something that the web teams that I have belonged to have done enough of. I once received an email from a librarian who asked me what was the process by which our web team came up with the final design. I told her that we had frequent meetings and we argued a lot. She didn’t write me back. So much for honesty.
Since most academic libraries are more alike than different – they all tend to do the same things but just at different scales – it’s not surprising that most academic library websites tend to resemble each other. We are all trying to ‘solve’ the same problems and so it should not be surprising that we come up with similar solutions. I’ve come to believe that there are only a small number of academic library website archetypes that result from the answers to some simple questions.
How Do We Fit Everything We Do On the Front Page?
Libraries do lots of things and, in general, they want all of the things that they do represented somewhere on the library’s front page (along with a sizable real estate dedicated to ‘library news’). If you want all your offerings represented on the front page, you have one of two choices: you have drop down or fly-out menus or you create categories where each service goes. If you opt for drop-down menus, the site tends to be made up of two or three columns of the most important text with the less important stuff in the menus. If you don't want these menus, then your site tends to run to four or five columns of text broken down into categories such as 'services' and 'resources'.
At MPOW, we also did something slightly different. We knew that we were restrained to two columns of text because of the web template of our university but we didn’t want to use drop-down or flyaway menus. So instead, we developed a philosophy that the main body of text on our website would be dedicated to services that we could foresee a student or researcher use every day: the library catalogue, our indexes, online journals, citation management, interlibrary loan (which, in an ideal world, would appear as a link in an index or library catalogue when a failed search occurred), booking a library computer, and book renewal (which admittedly doesn’t exactly fit the criteria of daily). Most everything else is found in the groups “About the Library”, “Research Help”, “Computer Help”, and “Writing Help”. The benefit of using this approach is that you are less likely to screw up the major deliverables that your website is supposed to provide. But there is a cost – some things do become lost.
The Search for Search
When we designed our library’s website, we thought that our sitemap would be the answer to the problem of our hidden content. But since then I have come to realize that the average user doesn’t look for a site map and have noticed that site maps are now becoming scarce in the rest of the online world. We have a link to a ‘search this site’ page but even though it has prime real estate on the front page – it is rarely used. Why? My hunch is that is that if users don’t see a search box on a web page, they will assume that no search function exists and won’t look elsewhere on the page for this. At the time of the re-design, we didn’t want to put a search box on our front page because we knew from experience that user will gravitate to it and automatically search what are looking for (title of a book, journal article, journal name, library hours) completely undaunted by whatever the search box is labeled.
Beyond The Question of Language
And yet we know that the choice of words is very important to the success of a web site. I think it’s now commonly understood that users will understand ‘books’ more than ‘library catalogue’ and understand either of those terms much more than a brand name such as ‘Infobridge’ or ‘Voyager’. What still not been excised from our way of thinking about academic library web sites is the word and the notion of ‘database’. As librarians, we tend to think of ourselves as a database supplier for our users. But the word ‘database’ means nothing to students. The same goes for the words ‘Resources’ or ‘E-Resources’. That’s because in the rest of our users’ online experiences, they are never asked to visit different ‘databases’ of a particular site. The solution is not just to find other words that make more sense (we use ‘Research Tools’) but to create a web experience in which the parts of a library’s online services come together as an integrated whole to make such labels unnecessary. I’m also hoping that our future academic website will resemble the non-scholarly world and present customized services and information about services through an ‘Account’ section.
An Aside
One of the reasons why I write is because I find it’s a helpful exercise for me to clear the fog and figure out what I know and what I don’t know. And as I have been writing this, I have again come to the realization that I don’t know as much as I thought when I started putting fingers to keyboard. That’s as good as a conclusion I can make at the moment : I think it’s a useful exercise for academic libraries to figure out and articulate what we know and what we don’t know about academic library web design. There’s so much to being honest.
I have been involved in such three library web redesign projects at MPOW over the years and have been meaning to write down some of the things that I think I have learned from the work before it becomes irrelevant. I want to qualify these statements as things I think I know because I can’t back up these statements with proper user testing. I am a huge advocate of re-iterative user testing but that’s not something that the web teams that I have belonged to have done enough of. I once received an email from a librarian who asked me what was the process by which our web team came up with the final design. I told her that we had frequent meetings and we argued a lot. She didn’t write me back. So much for honesty.
Since most academic libraries are more alike than different – they all tend to do the same things but just at different scales – it’s not surprising that most academic library websites tend to resemble each other. We are all trying to ‘solve’ the same problems and so it should not be surprising that we come up with similar solutions. I’ve come to believe that there are only a small number of academic library website archetypes that result from the answers to some simple questions.
How Do We Fit Everything We Do On the Front Page?
Libraries do lots of things and, in general, they want all of the things that they do represented somewhere on the library’s front page (along with a sizable real estate dedicated to ‘library news’). If you want all your offerings represented on the front page, you have one of two choices: you have drop down or fly-out menus or you create categories where each service goes. If you opt for drop-down menus, the site tends to be made up of two or three columns of the most important text with the less important stuff in the menus. If you don't want these menus, then your site tends to run to four or five columns of text broken down into categories such as 'services' and 'resources'.
At MPOW, we also did something slightly different. We knew that we were restrained to two columns of text because of the web template of our university but we didn’t want to use drop-down or flyaway menus. So instead, we developed a philosophy that the main body of text on our website would be dedicated to services that we could foresee a student or researcher use every day: the library catalogue, our indexes, online journals, citation management, interlibrary loan (which, in an ideal world, would appear as a link in an index or library catalogue when a failed search occurred), booking a library computer, and book renewal (which admittedly doesn’t exactly fit the criteria of daily). Most everything else is found in the groups “About the Library”, “Research Help”, “Computer Help”, and “Writing Help”. The benefit of using this approach is that you are less likely to screw up the major deliverables that your website is supposed to provide. But there is a cost – some things do become lost.
The Search for Search
When we designed our library’s website, we thought that our sitemap would be the answer to the problem of our hidden content. But since then I have come to realize that the average user doesn’t look for a site map and have noticed that site maps are now becoming scarce in the rest of the online world. We have a link to a ‘search this site’ page but even though it has prime real estate on the front page – it is rarely used. Why? My hunch is that is that if users don’t see a search box on a web page, they will assume that no search function exists and won’t look elsewhere on the page for this. At the time of the re-design, we didn’t want to put a search box on our front page because we knew from experience that user will gravitate to it and automatically search what are looking for (title of a book, journal article, journal name, library hours) completely undaunted by whatever the search box is labeled.
Beyond The Question of Language
And yet we know that the choice of words is very important to the success of a web site. I think it’s now commonly understood that users will understand ‘books’ more than ‘library catalogue’ and understand either of those terms much more than a brand name such as ‘Infobridge’ or ‘Voyager’. What still not been excised from our way of thinking about academic library web sites is the word and the notion of ‘database’. As librarians, we tend to think of ourselves as a database supplier for our users. But the word ‘database’ means nothing to students. The same goes for the words ‘Resources’ or ‘E-Resources’. That’s because in the rest of our users’ online experiences, they are never asked to visit different ‘databases’ of a particular site. The solution is not just to find other words that make more sense (we use ‘Research Tools’) but to create a web experience in which the parts of a library’s online services come together as an integrated whole to make such labels unnecessary. I’m also hoping that our future academic website will resemble the non-scholarly world and present customized services and information about services through an ‘Account’ section.
An Aside
One of the reasons why I write is because I find it’s a helpful exercise for me to clear the fog and figure out what I know and what I don’t know. And as I have been writing this, I have again come to the realization that I don’t know as much as I thought when I started putting fingers to keyboard. That’s as good as a conclusion I can make at the moment : I think it’s a useful exercise for academic libraries to figure out and articulate what we know and what we don’t know about academic library web design. There’s so much to being honest.
Wednesday, July 23, 2008
One reason books are beautiful - less diapers to worry about
OK, I am fully aware how silly this story will sound but parenting is serious business dammit.
The day after my son first read his new book Uh-Oh Gotta Go by Bob From Sesame Street he started using the potty on a consistent basis.
Its pretty incredible, when you think about it, that a simple picture book depicting happy toddlers using the potty can inspire a real two year old to do the same.
The day after my son first read his new book Uh-Oh Gotta Go by Bob From Sesame Street he started using the potty on a consistent basis.
Its pretty incredible, when you think about it, that a simple picture book depicting happy toddlers using the potty can inspire a real two year old to do the same.
Monday, July 21, 2008
Sunday, July 20, 2008
Using Google and FriendFeed to Create a Collaborative Research Environment
Some months ago, I suggested that one way to measure of a success of a library's discovery system is to compare it to Google. I've been thinking about extending this measuring stick to the rest of the support that libraries provide to their researchers. So, I created a Google account for a fictional Cloud Researcher.
After creating a Gmail account for "Cloud Researcher" I started a Google Reader account for her. It was shockingly easy to add an RSS feed of the most recent issues to the more well known journals such as Nature and Science. Now my researcher can stay up to date in her field.
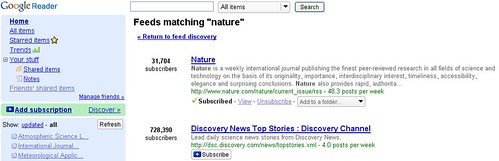
Google Reader makes it easy to share items by allowing instant publishing to a clippings blog. (This feature will prove important later on)

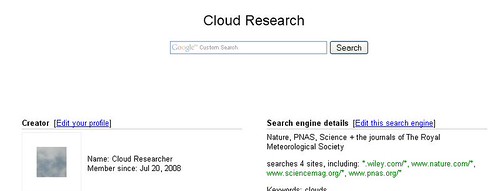
I then created a customized Google search engine so whenever my researcher needs to refer or research, she can just search this index of just the journals and websites that she trusts. If she wants to cast a wider net, she can always opt to search with Google Scholar or even plain old vanilla Google.
If her affiliated academic library provides authentication by IP address, then our researcher can keep up with her journal reading on campus without ever visiting the library's website even once - even if she's off-campus by using Windows XP Remote Desktop option to access her work computer. And if she has a loving, caring library, she can authenticate and access research using LibX, which also comes in handy when she uses Google Books.
I'm glad I actually went through the exercise of actualizing this example because in doing so, I had a small epiphany which was this: the future of learning online space is going to be an aggregation of online services. I realized this when I started playing with FriendFeed.
I've been using FriendFeed for about a week now and I still find it a strange beast. The way I would describe it is FriendFeed = Twitter + RSS reader. I think FF is an improvement on Twitter because it allows others to comment directly to a post. But FF is not a conventional RSS reader like Bloglines or Google Reader as the emphasis is on following friends - not publications. But what you can do with FriendFeed is create different 'rooms' for your different circle of friends. I created a room called The Cloud Research Lab Room.
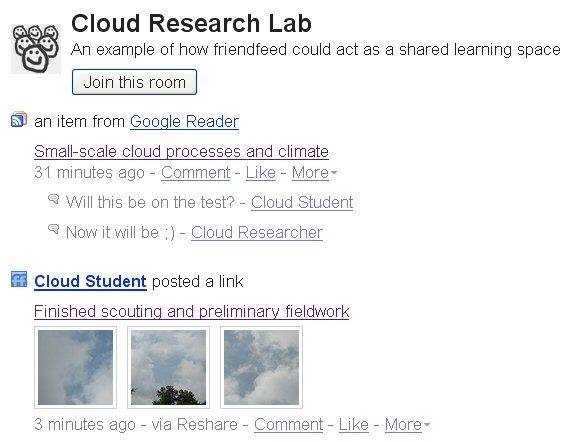
What would happen if FriendFeed could share structured bibliographic citations from Zotero?
I think it could be something wonderful.
After creating a Gmail account for "Cloud Researcher" I started a Google Reader account for her. It was shockingly easy to add an RSS feed of the most recent issues to the more well known journals such as Nature and Science. Now my researcher can stay up to date in her field.
Google Reader makes it easy to share items by allowing instant publishing to a clippings blog. (This feature will prove important later on)
I then created a customized Google search engine so whenever my researcher needs to refer or research, she can just search this index of just the journals and websites that she trusts. If she wants to cast a wider net, she can always opt to search with Google Scholar or even plain old vanilla Google.
If her affiliated academic library provides authentication by IP address, then our researcher can keep up with her journal reading on campus without ever visiting the library's website even once - even if she's off-campus by using Windows XP Remote Desktop option to access her work computer. And if she has a loving, caring library, she can authenticate and access research using LibX, which also comes in handy when she uses Google Books.
I'm glad I actually went through the exercise of actualizing this example because in doing so, I had a small epiphany which was this: the future of learning online space is going to be an aggregation of online services. I realized this when I started playing with FriendFeed.
I've been using FriendFeed for about a week now and I still find it a strange beast. The way I would describe it is FriendFeed = Twitter + RSS reader. I think FF is an improvement on Twitter because it allows others to comment directly to a post. But FF is not a conventional RSS reader like Bloglines or Google Reader as the emphasis is on following friends - not publications. But what you can do with FriendFeed is create different 'rooms' for your different circle of friends. I created a room called The Cloud Research Lab Room.
What would happen if FriendFeed could share structured bibliographic citations from Zotero?
I think it could be something wonderful.
Friday, July 18, 2008
Library Labyrinth
Perhaps it was my recent visit to IKEA or perhaps its from my daily lurking of Find The Lost Ring ARG (which is dedicated to the lost sport of Labyrinth Running), but I keep thinking that there should be a library that contains bookshelves organized so that they create a labyrinth path.
The meandering but purposeful path of the labyrinth is a metaphor for life. Unlike a maze, there is only one path in and out. There are no shortcuts, no dead ends, and the entire path must be followed to complete the journey. The labyrinth visually reminds us that we are walking a common path. Often circular in design, they represent wholeness and unity. Interest in the labyrinth as a tool for relaxation, healing, building community, solving problems, and nurturing intuition, creativity, and artistic expression has increased significantly over the past several years. They can be found in hospitals, parks, schools, prisons, retreat centers, faith- based organizations, and private gardens. [the library as labyrinth]
Thursday, July 10, 2008
Z for Zotero!
I've been holding out from using Zotero but I think I will be making the switch as soon as these features come out of beta:
I'm also particularly intrigued how Zotero and others will take advantage of RDF and the Semantic Web now that a Bibliographic Ontology has been established.
- synchronization of work from different computer browsers
- adoption of Endnote citation styles
- communication with the Internet Archive
- zeroconf!
I'm also particularly intrigued how Zotero and others will take advantage of RDF and the Semantic Web now that a Bibliographic Ontology has been established.
Monday, June 30, 2008
Search is a combination what you know and who you know
In my first years of academic librarianship, it struck me as really odd that I would have faculty call me up and ask me to teach their undergraduate students how to use the library indexes. Some of them would even confess that they really didn't know how to use these tools themselves.
In time, I came to realize two crucial points. First, faculty keep up with their research by regularly reading their personal journal subscriptions and keeping track of what the most important researchers in their field are doing. When they do use library-provided indexes, they tend to search by author and by following citations. Google Scholar recognizes this; when you search for Hamlet you get an article written by D. Hamlet as the first result returned.
The second point is that the process of learning who the key figures are in a particular field is part of the transformation from beginner to expert. The trouble is, our existing indexes are designed for librarians - not for students who are making this transition from undergraduate to graduate.
Rarely are students told that research is a reiterative process and that it is often necessary to perform a number of literature searches for a paper as one discovers gaps in coverage or realizes that there is something worth dwelling into more detail. But as seasoned librarians and educators know, even if you tell them this hard won nugget of wisdom, most students will still just grab the first set of articles that match their topic (which can be quite random especially if the database sorts results by date) and then try to mash these citations into their paper, often the night before its due.
So then how can we point these students to the best articles on a particular topic ?
One solution is to point beginning researches to sources of review articles. At the reference desk, I try to check Annual Reviews whenever I get a student who can't narrow down their research question to anything beyond their topic. You know the ones: "I need articles on anorexia." Another solution would be for us to take matters in our own hands. Here's my idea: we should buy the ten most popular textbooks for undergraduates in a particular domain, like Biology. Then we should make note of all the citations in the texts and add them into a searchable database.
These two examples still rely on the work of editors and experts to select the research that made a difference and to put such work in context. TopCited tools from Scopus and Web of Knowledge have been developed to automatically quantify the value of articles and researchers by the rate and number of times papers have been cited.
I believe that the adoption of social networking software into the academic sphere will eventually provide another means of establishing who are the experts in a particular field and what pieces of writing and research are the ones that have made the most impact. It very well might replace the traditional way we search and research and keep up with our fields.
Reading blogs is a case in point. You read library blogs on a regular basis rather than searching for the word 'library' in Google on a regular basis, don't you?
In time, I came to realize two crucial points. First, faculty keep up with their research by regularly reading their personal journal subscriptions and keeping track of what the most important researchers in their field are doing. When they do use library-provided indexes, they tend to search by author and by following citations. Google Scholar recognizes this; when you search for Hamlet you get an article written by D. Hamlet as the first result returned.
The second point is that the process of learning who the key figures are in a particular field is part of the transformation from beginner to expert. The trouble is, our existing indexes are designed for librarians - not for students who are making this transition from undergraduate to graduate.
Rarely are students told that research is a reiterative process and that it is often necessary to perform a number of literature searches for a paper as one discovers gaps in coverage or realizes that there is something worth dwelling into more detail. But as seasoned librarians and educators know, even if you tell them this hard won nugget of wisdom, most students will still just grab the first set of articles that match their topic (which can be quite random especially if the database sorts results by date) and then try to mash these citations into their paper, often the night before its due.
So then how can we point these students to the best articles on a particular topic ?
One solution is to point beginning researches to sources of review articles. At the reference desk, I try to check Annual Reviews whenever I get a student who can't narrow down their research question to anything beyond their topic. You know the ones: "I need articles on anorexia." Another solution would be for us to take matters in our own hands. Here's my idea: we should buy the ten most popular textbooks for undergraduates in a particular domain, like Biology. Then we should make note of all the citations in the texts and add them into a searchable database.
These two examples still rely on the work of editors and experts to select the research that made a difference and to put such work in context. TopCited tools from Scopus and Web of Knowledge have been developed to automatically quantify the value of articles and researchers by the rate and number of times papers have been cited.
I believe that the adoption of social networking software into the academic sphere will eventually provide another means of establishing who are the experts in a particular field and what pieces of writing and research are the ones that have made the most impact. It very well might replace the traditional way we search and research and keep up with our fields.
Reading blogs is a case in point. You read library blogs on a regular basis rather than searching for the word 'library' in Google on a regular basis, don't you?
Thursday, June 26, 2008
Boolean NOT
I have been thinking about social software and libraries and I suspect that the result of this thinking might be a rash of posts not unlike a bunch I wrote when I couldn't stop thinking about Wikipedia.
But before I can write about how I think social software may affect search and research, I feel its necessary to clear some cognitive space first. So before proceeding, I want to make something very clear: LIBRARIANS HAVE TO STOP TEACHING BOOLEAN SEARCHING.
I know this is scary stuff for many academic librarians who I suspect would be at a loss of what to teach if you took away their ((ANDs) and (ORs)). But teaching about Boolean logic has become a crutch and its time to throw it away. I would go so far to say that banning the word Boolean is the number one way to improve information literacy practice in libraries.
You see, most people don't use Boolean searching. And they are still healthy, happy, and successful people. Sure, they may not be the most searching in the most efficient way but their searching is still effective. Users want to apply their energies to their results and not to search grammar.

It is far more efficient to create searching interfaces that try to address these behaviour patterns than try to educate everyone of the masses on "the right way" to search.
We are at a state where the bibliographic databases have become so large that even some of the worst, poorly constructed search terms now bring relevent hits among the debris. Unfortunately, one response I've seen first hand is a library assignment in which the student is forced to use boolean logic by requiring that only 10 hits or less be returned from a search string. Any research assignment does not resemble how a real person conducts research is a poor one, to say the least.
Instead teaching that AND means 'and' and 'OR' means 'or', we should try to teach something beyond the mechanics of search. Instead of teaching about Boolean, we should instruct on the importance of language, on the nature of the publication cycle, and of the research process.
And it goes without saying that we have to get the word Boolean out of our library catalogues.
But before I can write about how I think social software may affect search and research, I feel its necessary to clear some cognitive space first. So before proceeding, I want to make something very clear: LIBRARIANS HAVE TO STOP TEACHING BOOLEAN SEARCHING.
I know this is scary stuff for many academic librarians who I suspect would be at a loss of what to teach if you took away their ((ANDs) and (ORs)). But teaching about Boolean logic has become a crutch and its time to throw it away. I would go so far to say that banning the word Boolean is the number one way to improve information literacy practice in libraries.
You see, most people don't use Boolean searching. And they are still healthy, happy, and successful people. Sure, they may not be the most searching in the most efficient way but their searching is still effective. Users want to apply their energies to their results and not to search grammar.
It is far more efficient to create searching interfaces that try to address these behaviour patterns than try to educate everyone of the masses on "the right way" to search.
We are at a state where the bibliographic databases have become so large that even some of the worst, poorly constructed search terms now bring relevent hits among the debris. Unfortunately, one response I've seen first hand is a library assignment in which the student is forced to use boolean logic by requiring that only 10 hits or less be returned from a search string. Any research assignment does not resemble how a real person conducts research is a poor one, to say the least.
Instead teaching that AND means 'and' and 'OR' means 'or', we should try to teach something beyond the mechanics of search. Instead of teaching about Boolean, we should instruct on the importance of language, on the nature of the publication cycle, and of the research process.
And it goes without saying that we have to get the word Boolean out of our library catalogues.
Tuesday, June 24, 2008
If there is no porn in your library catalogue, then its not working
"Based on my Tripod experience, I’d offer the hypothesis that any sufficiently advanced read/write technology will get used for two purposes: pornography and activism. Porn is a weak test for the success of participatory media - it’s like tapping a mike and asking, “Is it on?” If you’re not getting porn in your system, it doesn’t work. Activism is a stronger test - if activists are using your tools, it’s a pretty good indication that your tools are useful and usable." [The Cute Cat Theory Talk at ETech]
Friday, June 20, 2008
reddit.com: Who else is sick of sites hosting research papers that show all their content to Google so it gets indexed, but when people visit, they want you to pay exorbitant fees?
reddit.com: Who else is sick of sites hosting research papers that show all their content to Google so it gets indexed, but when people visit, they want you to pay exorbitant fees?
Some of the comments are quite entertaining:
Also interesting is that the discussion immediately proceeds into the realm of IP spoofing and cloaking. Check your library for holdings? Nah - pretend to be Googlebot to get a free pass!
Wednesday, June 18, 2008
My definition of a boombatic library blog
I’ve also heard librarians discussing the same concept in the library community. In library-related articles, blog posts, and presentations I’ve attended and/or read this past year, the presenters/writers have been saying that Web 2.0 and Library 2.0 are all about starting conversations, building community, and telling our stories. But the writer/presenter tends to skip over what I think is the most important part - they never explain how to do it. [David Lee King]
David Lee King makes the case that a library (blog) should invite participation or, if possible, be actionable. While I find this ambition admirable, I don't entire agree with it. I subscribe to the "you use a library, you don't make friends with it" school of library twotopianism.
This is my suggestion on how to do it: use your library (blog) to connect readers with readings. Or, more generally, make every post a connection between your library and the world they live in.
Here are the specifics. First, think about how your readers decide what book or article to read next. Chances are, they don't use your library or its OPAC to decide what to read. Your readers rely on the recommendations of their friends and/or from their reading of newspapers, magazines, journals and even blogs.
So, as you read your magazines or your local or national newspaper, online or otherwise, make note of the books, government reports, and scientific papers mentioned and see if its available through your library. Heck, you can do the same for books that you've head mentioned on the radio. Even if the government report scientific paper you read about is free online, your readers will appreciate the direct link to it as it will save *them* the aggravation of having to navigate the Statistics Canada website, for example.
The benefits of such blogging is multifold. Not only does it help the reader, this regular reading helps the librarian in keeping up with the world. Checking to see if you have the books that are currently being reviewed in the press is a great way to measure how successful your library's approval plan is working (or not). Furthermore, the librarian gains a stronger understanding of their strengths of the library's collection through what I'd like to call, curiousity-based collection development.
Here's an example of it: some months ago I was curious if the library at MPOW had The Pillars of the Earth, a recent book recommended by Oprah. At the time, when I checked what readers had said about the book on Amazon, it told me that folks who bought that book also were interested in Cathedral: The story of its construction by David Macaulay. Following that link, I learned that this was the same man responsible for The Way Things Work (which we had in our library's education collection) and The New Way Things Work (which we did not).
I'm not enirely that fond of the notion that the library blog is a tool of conversation between a library and its users - at least, not in the sense of how The Cluetrain Manifesto uses it. Reading is the real conversation.
Monday, June 16, 2008
Server on a stick
Occasionally, I feel bad that my computer skills have large stagnated.
My excuse, which I would use to comfort myself, was that I didn't have ready access to a server and thus, no ready access to advanced computer languages or advanced applications.
Now, this wasn't much of an excuse: there are web hosting companies that provide access to languages such as PHP and I know computer folks who are generous with their help. But still - access to a server would require effort. And as long as there was that barrier of effort required, I had my excuse for my ignorance.
That is, until I realized that not only can you run applications like WorkPress and Django on a USB stick.
My excuse, which I would use to comfort myself, was that I didn't have ready access to a server and thus, no ready access to advanced computer languages or advanced applications.
Now, this wasn't much of an excuse: there are web hosting companies that provide access to languages such as PHP and I know computer folks who are generous with their help. But still - access to a server would require effort. And as long as there was that barrier of effort required, I had my excuse for my ignorance.
That is, until I realized that not only can you run applications like WorkPress and Django on a USB stick.
Wednesday, June 11, 2008
Librarianship and journalism - are they connected?
2008jun10. The 35 articles of impeachment introduced by Dennis Kucinich yesterday. Not covered by NYT FOX CBS ABC CBS CNN etc mmm big MSM luv you bet
Anyone who watches The Colbert Report knows that the MSM is both high comedy and high tragedy. The Daily Show is a daily reminder that 'the news' is just directed attention to events construed by a small group of editors. One could say that it has always been this way. Unless news outlets realize that investigative journalism is their critical function, their days of printing money may be over.
I am interested in libraries, blogging, the media, and open government and I think I've thought of one instance where they all intersect. We clearly cannot trust MSM to bring attention to the day's important events and discoveries. That is why it is essential that an archive of the raw material of news - the press releases, the government reports, the committee agendas and minutes, the legislature, the video feeds, the full-text of budgets - should be made available to all for word-of-mouth reporting.
And just like the news media, the library's critical function of being a subsidized source of organized information is also being eroded by the Internet. It used to be that if you wanted to find a newspaper older than a couple of days, you had to go to your public library to get it. We could do worse that provide our citizens with the information that they can't get from the MSM.
Wednesday, May 28, 2008
If they say that is "going green" then I say "goodbye polar bears"
Whenever I read about a library conference that goes green by banning presentation handouts, I don't know whether to laugh or to cry or to release tanks of methane into the auditoriums.
Honestly, how could grown adults act so self-congratulatory over such a insanely pathetic and inane action when compared to the scale of the environmental problems that are at hand.
Oh yeah, we just happen to be a profession that BUYS ENTIRE BOOKS for our communities. Stop us before we kill again!
Honestly, how could grown adults act so self-congratulatory over such a insanely pathetic and inane action when compared to the scale of the environmental problems that are at hand.
Oh yeah, we just happen to be a profession that BUYS ENTIRE BOOKS for our communities. Stop us before we kill again!
Tuesday, May 27, 2008
Peer reviewed versus peer to peer
There has been some chatter as of late in the library blogosphere in which there has been talk of supplanting library peer-reviewed journals with library blogs. Dorothea has provided my favourite response to the matter but I do want to add one little tiny thought.
I suspect one of the things that is holding the (inevitable) transition to unmediated online writing through self-publishing software is the the fact that words blog and blogger still sound ridiculous (hover over image for alt-tag).
I suspect one of the things that is holding the (inevitable) transition to unmediated online writing through self-publishing software is the the fact that words blog and blogger still sound ridiculous (hover over image for alt-tag).
Tuesday, May 20, 2008
You can and must understand computers NOW

One of the reasons why I was so disappointed with the One Laptop Per Child's decision not to support teachers in their supposed mission of educating children is because I know that its not enough to put a computer in front of a child and expect that a savvy computer user will emerge in time.
I know this because when I was young, my gadget-loving dad brought home an Apple IIe and for the life of me, I couldn't make it do anything but use it for word processing and to play games that one my dad's co-workers kindly copied for us. It wasn't that I wasn't interested in computers. By that time I had already taken a couple "computers for young people" classes through the local community college. But my knowledge of BASIC did me no good and the manuals that Apple provided may as well been written in binary. The computer was a black box with big floppy disks.
Fast forward to high school. I was one of 3 or 4 girls in a computer class and we pretty much kept to ourselves. Eventually our classmate Brian would occasionally join us in our corner and amuse us with stories. After we gave him our respective username and passwords ( a strange trust exercise / friendship ritual that kids continue to do today) he somehow created little animated stick drawings that would display when we logged in at our terminals at the beginning of class. Somehow Brian had learned to do all sorts of cool and strange things that were never mentioned in class. When I asked him how he figured all this out, he told me that he and a small group of guys would hang out in the computer lab and over time had picked up tricks from each other and the teacher who was supportive of their interests.
Similarly, I eventually figured out that many computer enthusiasts became what they are through the help of other computer enthusiasts through user groups, or BBS, or Usenet.
In short, it takes a village to raise a geek.
Now, through the miracle that we call the Internet, its even easier to learn how to learn about computing. There are all sorts of manuals, FAQs and tutorials about like the newly resurrected webmonkey which I used some years ago to build my own HTML skills. And more importantly, there are kind people like Dan Chudnov who are willing to help you to learn2code.
The support is there. You just have to figure a project that you want to do and then beat things with rocks until its working.
Monday, May 19, 2008
OLPC : hubris or fraud
Until now, I had chalked up OLPC founder Nicolas Negroponte's disdain for teachers and software support as an extreme strain of faith in the innate computer capabilities of children and the common person.
I'm sad to say that recent evidence suggest that the reality might be much bleaker: that the OLPC program was and is only about the distribution of laptops.
I'm not so much sad over the failure of this particular program as sad over all the volunteer efforts and international goodwill that has been recklessly spent.
I'm sad to say that recent evidence suggest that the reality might be much bleaker: that the OLPC program was and is only about the distribution of laptops.
I'm not so much sad over the failure of this particular program as sad over all the volunteer efforts and international goodwill that has been recklessly spent.
Tuesday, May 13, 2008
University of Michigan education professor David Cohen says that no education occurs until what he calls “inert” assets (books, teachers, rooms, curricula, rules, budgets, and so on) interact with each other and with students. Education is interaction. People in educational organizations, he says, often behave as if the inert assets were essential and the interactions expendable. They fight political wars over budgets, space, and personnel, and spend little time defending and perfecting the interactions among these assets through cooperation, communication, teamwork, and knowledge about students.
The above passage struck me as having a direct parallel to some of the recent changes I've noticed in academic librarianship. Putting it in broad strokes, we are going through a fundamental shift in libraries from being collection-focused to being user-focused. What I like about the above quotation is that spending time "perfecting the interactions among these assets through cooperation, communication, teamwork, and knowledge about students" sounds very much like what good Information Literacy practice aspires to be.
Its from an essay that calls for a fundamental organizational change in health care titled Escape Fire: Lessons for the Future of Health Care [pdf]. I read this essay because of this recommendation to do from Brett Bonfield on the ACRL blog. And I would second the recommendation. Its worth reading for its own merits relating to health care and for reminding us how important transparency and access to information can be in a person's life.
Thursday, May 08, 2008
Freedom for our FOIA
While on leave from libraryland, I'm still keeping touch through the library blogosphere. And in doing so, I noticed that none of the Canadian library blogs that I follow had made mention that the Harper government recently told all federal agencies to stop providing monthly updates to the public of all the requests it is answering under the Access to Information Act.
The Freedom of Information Act (FOIA) is one of the few tools that ordinary citizens can use to keep their government accountable. In my hometown, a citizen recently took on our excessively secretive city council with a FOIA and now we know the details of an arena contract between the city of Windsor and the local OHL hockey franchise.
When I was in library school at McGill, I wrote a loving profile of Ken Rubin, another private citizen who uses FOIA much to the chagrin to those in power -- and I am glad to say that I am not the only one to do so. But I think librarians should do much more to support the cause. Here's a start: every library's government document's web presence should provide a link and instructions how to place a Freedom of Information Act.
And if the CAIRS database is not reinstated, then I wish and hope that a library out there will create a Canadian version of WhatDoTheyKnow.
The Freedom of Information Act (FOIA) is one of the few tools that ordinary citizens can use to keep their government accountable. In my hometown, a citizen recently took on our excessively secretive city council with a FOIA and now we know the details of an arena contract between the city of Windsor and the local OHL hockey franchise.
When I was in library school at McGill, I wrote a loving profile of Ken Rubin, another private citizen who uses FOIA much to the chagrin to those in power -- and I am glad to say that I am not the only one to do so. But I think librarians should do much more to support the cause. Here's a start: every library's government document's web presence should provide a link and instructions how to place a Freedom of Information Act.
And if the CAIRS database is not reinstated, then I wish and hope that a library out there will create a Canadian version of WhatDoTheyKnow.
Thursday, May 01, 2008
A Library Fortress of Silentude? | Ask Metafilter
A Library Fortress of Silentude? | Ask Metafilter:
"There is a war going on in the library. This conflict is between students who seek solitary silent study and those who seek to study or work on projects in groups. An individual student's allegiance to a faction can change from day to day based on their current course load. Because the Grouparians have the advantage of numbers, they tend to win out over the Solitarites. Surely the latter group needs a fortress all their own?"
Tuesday, April 29, 2008
Sunday, April 27, 2008
Kill your television
My sibling and I have had an ongoing conversation about the dearth of meaningful volunteer work and share a frustration that more non-profit groups don't make more use of the Internet's potential.
We're not the only one's who have recognized the untapped potential that exists. Clay Shirky has too - but has quantitfied it and put into a historical context in his recent essay, Gin, Television, and Social Surplus. It's highly recommended reading.
We're not the only one's who have recognized the untapped potential that exists. Clay Shirky has too - but has quantitfied it and put into a historical context in his recent essay, Gin, Television, and Social Surplus. It's highly recommended reading.
Wednesday, April 16, 2008
XO Laptop - beautiful but tragically flawed
So yesterday I entertained my 2 1/2 year old son by bringing out my XO laptop from OLPC.
The XO laptop is designed for children from ages 6 to 12 but there are some activities that a small child can explore. Mats likes making noise with TamTamMini and making B I G L E T T E R S with Write, its text editing program. But it was the ability to capture video that made him scream and drool with delight (thank goodness for the xo's water resistant keyboard).
But like so many times before, my delight in the XO laptop quickly evaporated into pure frustration. After the little one had gone to bed, I turned on my XO to find that I could not view any of the videos I had just recorded of my little guy. I sighed and then, with a growing sense of dread, I went online to see if someone else had experienced the same problem. I had been down this road before - and it wasn't pretty.
You see, there are multiple sources of support for the XO. There is the official OLPC Wiki - which suffers from a severe lack of editorial work. Don't believe me? This is what I mean: there is a community user guide, a new user guide, a workaround section, the "official FAQ" and the support FAQ, the Ask OLPC A Question section (which has its own archive), and of course, separate pages for the various aspects of hardware and software which often have different information than the guides. And supplementing the wiki, there are two support discussion forums: the official one and the OLPC News Forum. And supplementing those are mailing lists (public, community and official ones) and, if you like your help old-skool-stylee, there are several IRC channels on the subject of the OLPC.
Trouble is, not a single person is dedicated to answering any of the questions. Evidently children are going to do the job but in the meantime, its just volunteers.
You see, the founder of OLPC Nicholas Negroponte, doesn't believe in product support for the XO. According to Negroponte, I should be asking a small child to teach me how to use my laptop because, "with all due respect" to those who believe that education depends teachers, schools, curriculum, or content, success is dependent "on leveraging the children themselves".
Except that the XO is buggy as hell.
I *understand* how video should work. But it doesn't. And after hours of searching wikis and forums, I now know that at least one person has experienced the same problem since January and that no one has offered a possible solution yet.
I have a lot of faith in the power of online communities but unlike the OLPC organization, I don't take such groups for granted. The Open Source community is a beautiful one but they are more likely to take the time to answer a question that can be answered in python than to take the time to do the multi-step analysis required to find out why, for a presumed small group of users, playing recorded video doesn't work.
Non-working video hasn't been the first problem I've encountered. When I try to register my XO nothing happens. Evidently, the Write activity is able to save text as html but when I bring up my code in Browse, it refuses to recognize the code (there are TWO pre-installed activities dedicated to learning programming in Python and nothing to create a simple webpage?!?).
Hardware-wise, the XO laptop is a thing of beauty. But until a core group of XO activities can be developed to perform solidly and consistently, I don't think an entire nation should invest in these laptops for their children.
The XO laptop is designed for children from ages 6 to 12 but there are some activities that a small child can explore. Mats likes making noise with TamTamMini and making B I G L E T T E R S with Write, its text editing program. But it was the ability to capture video that made him scream and drool with delight (thank goodness for the xo's water resistant keyboard).
But like so many times before, my delight in the XO laptop quickly evaporated into pure frustration. After the little one had gone to bed, I turned on my XO to find that I could not view any of the videos I had just recorded of my little guy. I sighed and then, with a growing sense of dread, I went online to see if someone else had experienced the same problem. I had been down this road before - and it wasn't pretty.
You see, there are multiple sources of support for the XO. There is the official OLPC Wiki - which suffers from a severe lack of editorial work. Don't believe me? This is what I mean: there is a community user guide, a new user guide, a workaround section, the "official FAQ" and the support FAQ, the Ask OLPC A Question section (which has its own archive), and of course, separate pages for the various aspects of hardware and software which often have different information than the guides. And supplementing the wiki, there are two support discussion forums: the official one and the OLPC News Forum. And supplementing those are mailing lists (public, community and official ones) and, if you like your help old-skool-stylee, there are several IRC channels on the subject of the OLPC.
Trouble is, not a single person is dedicated to answering any of the questions. Evidently children are going to do the job but in the meantime, its just volunteers.
You see, the founder of OLPC Nicholas Negroponte, doesn't believe in product support for the XO. According to Negroponte, I should be asking a small child to teach me how to use my laptop because, "with all due respect" to those who believe that education depends teachers, schools, curriculum, or content, success is dependent "on leveraging the children themselves".
Except that the XO is buggy as hell.
I *understand* how video should work. But it doesn't. And after hours of searching wikis and forums, I now know that at least one person has experienced the same problem since January and that no one has offered a possible solution yet.
I have a lot of faith in the power of online communities but unlike the OLPC organization, I don't take such groups for granted. The Open Source community is a beautiful one but they are more likely to take the time to answer a question that can be answered in python than to take the time to do the multi-step analysis required to find out why, for a presumed small group of users, playing recorded video doesn't work.
Non-working video hasn't been the first problem I've encountered. When I try to register my XO nothing happens. Evidently, the Write activity is able to save text as html but when I bring up my code in Browse, it refuses to recognize the code (there are TWO pre-installed activities dedicated to learning programming in Python and nothing to create a simple webpage?!?).
Hardware-wise, the XO laptop is a thing of beauty. But until a core group of XO activities can be developed to perform solidly and consistently, I don't think an entire nation should invest in these laptops for their children.
Monday, March 31, 2008
Tuesday, March 04, 2008
Ontario Scholars Portal – Yours to a Discovery Layer
(This is a little something I wrote to support this work)
What is a “Discovery Layer”?
To me, a Discovery Layer allows a user to search across a library catalogue (or several), an ebook platform (or several), and a source of articles (or several).
The challenges that face the construction of a discovery layer include:
What is a “Discovery Layer”?
To me, a Discovery Layer allows a user to search across a library catalogue (or several), an ebook platform (or several), and a source of articles (or several).
A Discovery Layer could make use of one or more combinations of the following:
- Federated Searching
- a query is distributed to multiple sources, and responses are compiled, de-duped, and returned
- e.g. Sirsi Single Search
- Metasearching
- a single, regularly complied index is created from the collection of metadata from multiple sources
- e.g. Endeca, Google
- Single host environment
- metadata and content are placed on a common server
- e.g. WorldCat, Ontario Scholars Portal
Why a Discovery Layer?
The pursuit of a Discovery Layer seem to be driven by the need to present one, strong and stable user interface over many disparate sources of information. Some benefits of a discovery layer include:
- users only have to learn one interface, instead of many
- users don’t have to choose from lists of dozens of indexes
- users don’t have to repeat searches depending on format (one search for books, then one for dissertations, then one for articles…)
- users expect simple, effective search tools like Google
The challenges that face the construction of a discovery layer include:
- many of our research tools are very difficult to extract data from as they make use of a multitude of non-standard formats and protocols
- most of our research tools (especially the library catalogue) generate search results with poor relevance ranking
- some sources will be rich in text and metadata (articles, ebooks) while other sources will only be represented by metadata (print books)
How much can an improved interface improve things?
- The second uses facets, like Endeca, WorldCat, and VuFind
How much can an improved interface, improve relevant results?
Coming up with what a user might deem relevant from 2 or 3 keywords is challenging in a regular search environment. Producing consistently relevant results in a federated or metasearch environment is extremely difficult.
Coming up with what a user might deem relevant from 2 or 3 keywords is challenging in a regular search environment. Producing consistently relevant results in a federated or metasearch environment is extremely difficult.
Relevance might be improved through one or more of the following:
- by taking into account the user’s previous searching behaviour
- by weighing results by the number of times an item has been bookmarked, printed, or saved
- by using citation information to determine ‘likeness’ (e.g. based on a percentage of shared citations in item’s bibliography)
- by using user-created lists articles to generate similar items of possible interest
- by knowing what courses a users is currently taking/teaching and emphasizing relevant resources accordingly
What is a Good Enough Discovery Layer?
Is it realistic to expect a Discovery Layer to serve both the novice researcher and the expert to access a variety of formats in a multitude of disciplines? Can one size fit all? Should we develop several Discovery Layers with one for each discipline? (Arts, Social Sciences, Medicine). Should we develop one interface for undergraduates and one for faculty and graduate students?
Is it realistic to expect a Discovery Layer to serve both the novice researcher and the expert to access a variety of formats in a multitude of disciplines? Can one size fit all? Should we develop several Discovery Layers with one for each discipline? (Arts, Social Sciences, Medicine). Should we develop one interface for undergraduates and one for faculty and graduate students?
How will we know we have reached the Promised Land?
Most discovery layers are still in the earliest stages of their development and by appearances, they seem more alike than unalike. How should we choose what is an acceptable product? One suggestion is to measure the success of a Discovery Layer by comparing its search results to Google.
Most discovery layers are still in the earliest stages of their development and by appearances, they seem more alike than unalike. How should we choose what is an acceptable product? One suggestion is to measure the success of a Discovery Layer by comparing its search results to Google.
Thursday, February 28, 2008
Libraries COE
Sun Microsystems, The University of Alberta Libraries and The Alberta Library create Centre of Excellence for Libraries: "SANTA CLARA, CA February 27, 2008 Sun Microsystems of Canada Inc., the University of Alberta Libraries (UAL) and The Alberta Library (TAL) today announced the creation of a new Sun Centre of Excellence for Libraries (COE)."
Wednesday, February 27, 2008
Digg + Local Library Purchases
Digg + Local Library Purchases: "So here’s my idea: take the engine that runs Digg, the “social news” website, and repurpose it as a web application that allows library patrons to collectively decide which books the library system should purchase. Patrons would “login” to “LibraryDigg” with their regular library card number and password, and then could enter books, DVDs, etc. that they want opened up for consideration." [Distant Librarian]
What I really like about this idea is that this service would provide public feedback illustrating what the library community is interested in and what are their unmet desires. I'm positive that this sort of information would be of interest to more than librarians as in my library, one can always see users check out the responses on the library's complaints bulletin board (which one day I would love to put online like Carleton's Dear Library service.)
But I'm not sure that I would use the Digg engine. I check out Digg and Reddit frequently and its not exactly a secret that the system is constantly being gamed (e.g. "Garbage can be turned into oil through a green method. We dispose of enough garbage per year to create a years worth of usable oil! Why aren't we funding these guys millions! UP VOTE THIS!!").
Instead, I would be more inclined to use something more independent engine to determine popularity.
Digg's Design Dilemma - Bokardo : The result of all these factors is that Digg breaks the cardinal rule of voting: independence. As outlined in James Surowiecki’s book The Wisdom of Crowds, independence arises when a person makes a decision (votes, diggs) without the direct influence of others, on their own, by making up their own mind. Of course, there will always be influences on that decision…what others have said, where their political party is leaning, their current situation, but in the end they need to have the privacy of their vote. On Digg, no votes are private, and when you make them you can’t help but notice the way others are voting...
The voting on Digg is in contrast to a site like Del.icio.us, where voting (saving a bookmark) is done more independently, often without having any idea whether or not someone else even viewed it, let alone voted on it... On Del.icio.us, the main value is personal, as people use it to store bookmarks that are valuable to them. On Digg, the bookmarking utility is secondary to the voting, in both the interface and the wording used on the site.
This all being said, I do support the notion that a library community can be trusted to select some of the materials that can be found in *their* library.
Tuesday, February 26, 2008
Riddle me this at your library
The MIT Libraries Puzzle Challenge is a series of puzzles released during the MIT semester. The series began with three puzzles in the Fall 2007 semester, and will continue with three more puzzles during the Spring 2008 semester. Puzzles are produced with the dual goals of being fun for our community and of introducing solvers to resources they might not otherwise know about.
My personal epiphany that there was a natural connection between puzzle games, learning, and libraries happened while I was playing the World Without Oil ARG and read as strangers on a forum thread worked together to identify a foreign language used in a video clue (Bulgarian) and then translate and transcribe the speech within hours.
I'm not the only one to have made this connection.
And MIT has been playing puzzle games with their students for over 25 years.
Saturday, February 23, 2008
Read about Griefers. Then be one
I've had a long standing prejudice that if you rely on WIRED magazine in order to understand Internet culture, then you probably are not particularly WIRED.
But two things have happened since I've made this conclusion : WIRED has become a much better magazine (I'm talking since the days from when they would lovingly profile venture capitalists and worship corporate heroes). And I've become older and (more) out of touch.
The article that made me come to this realization is from February issue of WIRED (16.02) and is called Mutilated Furries, Flying Phalluses: Put the Blame on Griefers, the Sociopaths of the Virtual World. Before this article, I knew that griefers existed but didn't know much more about them than that. After this article, I'm shocked to say, that I have now some small sympathy for their cause : the battle against "The Internet is Serious Business." I can't and won't excuse the worst of their behaviour (the death threats, for one) but now I can see the humour in the crassness and the method in the madness.
This deeper understanding has helped navigate the world of the very offensive and very amusing forumwarz [waxy]. In this role-playing game about the Internet, I'm playing a Troll. Who knew being a griefer was so much fun?
[cross-posted on NJA]
But two things have happened since I've made this conclusion : WIRED has become a much better magazine (I'm talking since the days from when they would lovingly profile venture capitalists and worship corporate heroes). And I've become older and (more) out of touch.
The article that made me come to this realization is from February issue of WIRED (16.02) and is called Mutilated Furries, Flying Phalluses: Put the Blame on Griefers, the Sociopaths of the Virtual World. Before this article, I knew that griefers existed but didn't know much more about them than that. After this article, I'm shocked to say, that I have now some small sympathy for their cause : the battle against "The Internet is Serious Business." I can't and won't excuse the worst of their behaviour (the death threats, for one) but now I can see the humour in the crassness and the method in the madness.
This deeper understanding has helped navigate the world of the very offensive and very amusing forumwarz [waxy]. In this role-playing game about the Internet, I'm playing a Troll. Who knew being a griefer was so much fun?
[cross-posted on NJA]
Monday, February 18, 2008
The Big Why About The Big Here
Its early evening. The Toddler is in bed. Right now is a short period of personal time before the promise of sleep will lure me to bed before the rest of the world settles in to watch primetime television. For some days now, this is the time where I begin researching answers to such questions as
I've been meaning to complete The Big Here Quiz ever since I first stumbled upon it in an issue of Whole Earth Review years ago and I've finally hit its half-way point. Its 30 questions are meant to inspire watershed awareness but in doing the quiz I've found that it has generated more than just a stronger curiosity and connection to where I live. It is making me a better librarian.
Finding who can delivery pizza to your house is not hard. Finding out whether "the soil under your feet, more clay, sand, rock or silt?" is surprisingly hard. Determining out how water gets into your tap and tracing where it goes after its sent down the drain is largely dependent on how much information your local utilities care to share with you. The information you need to finish this quiz can largely be found online, but in forms that have been fragmented and rebound depending on government level, jurisdictions, and departmental politics. (Watersheds transcend such boundaries).
By doing this quiz, I have been reintroduced to many government document websites that I have not visited in a long, long time. Many of these sites now feature GIS driven datasets which with a bit of trial and error, can usually be cajoled to produce information but the results are usually disappointingly thin. I'm waiting for the next generation of localized collections of data visualizations but I think it will be a long, long time before EveryBlock comes to Windsor, Ontario.
Like a good homework assignment, it is the curiosity that stretches while pursuing the question which is more important than the "answer". Now I'm wondering about the worms in my backyard, whether I really understand the concept of azimuth, and where is that closest fault line...
Where is the nearest earthquake fault? When did it last move?
I've been meaning to complete The Big Here Quiz ever since I first stumbled upon it in an issue of Whole Earth Review years ago and I've finally hit its half-way point. Its 30 questions are meant to inspire watershed awareness but in doing the quiz I've found that it has generated more than just a stronger curiosity and connection to where I live. It is making me a better librarian.
Finding who can delivery pizza to your house is not hard. Finding out whether "the soil under your feet, more clay, sand, rock or silt?" is surprisingly hard. Determining out how water gets into your tap and tracing where it goes after its sent down the drain is largely dependent on how much information your local utilities care to share with you. The information you need to finish this quiz can largely be found online, but in forms that have been fragmented and rebound depending on government level, jurisdictions, and departmental politics. (Watersheds transcend such boundaries).
By doing this quiz, I have been reintroduced to many government document websites that I have not visited in a long, long time. Many of these sites now feature GIS driven datasets which with a bit of trial and error, can usually be cajoled to produce information but the results are usually disappointingly thin. I'm waiting for the next generation of localized collections of data visualizations but I think it will be a long, long time before EveryBlock comes to Windsor, Ontario.
Like a good homework assignment, it is the curiosity that stretches while pursuing the question which is more important than the "answer". Now I'm wondering about the worms in my backyard, whether I really understand the concept of azimuth, and where is that closest fault line...
Sunday, January 20, 2008
OLPC and the Library : The Talk
If you are in the Windsor / Detroit area, please consider joining a talk sponsored by MPOW called:
One Laptop Per Child: Open Source, Open Access, Open Library
January 28th, 7 pm, Freed-Orman Centre
By attending, you could win your very own XO laptop!
There's an article about the OLPC in the Toronto Sunday Star. What I found very amusing is that I share the journalist's same sensibility towards simple computers: he used to own an eMate and I used to lust after one.
One Laptop Per Child: Open Source, Open Access, Open Library
January 28th, 7 pm, Freed-Orman Centre
By attending, you could win your very own XO laptop!
There's an article about the OLPC in the Toronto Sunday Star. What I found very amusing is that I share the journalist's same sensibility towards simple computers: he used to own an eMate and I used to lust after one.
Tuesday, January 08, 2008
Today my guest post at OLPC got published
Today the OLPC News blog kindly printed a guest post of mine about the relationship between libraries and the work of the One Laptop Per Child program.
That's the good news. The bad news is that evidently, there were only 4000 orders for XO laptops from Canada and that due to shipping logistics, the Canadian deliveries have been pushed back until February 15th!
That's the good news. The bad news is that evidently, there were only 4000 orders for XO laptops from Canada and that due to shipping logistics, the Canadian deliveries have been pushed back until February 15th!
Thursday, January 03, 2008
OLA wants your picutres of libraries from around the world
The Ontario Library Association's Super Conference 2008 is asking
Do you have pictures of photos of libraries you've snapped in your travels? If you’ve got some hidden away on your hard drive or in a photo album please help us by submitting them to OLA. Photos of any kinds of libraries (or librarians) in any location are good...I'll be at this year's Super Conference for Friday only and will be speaking on that day with Stacy Allison-Cassin in Session #1318: Scholar's Portage: Leveraging Social Networking Tools and Scholars Portal Data.
Photos will be used in a gallery on the OLA Super Conference Web site, at plenary sessions throughout the conference and, most particularly, at the closing plenary on Saturday, Feb. 2nd during the luncheon in which incoming IFLA President Ellen Tise from South Africa will be speaking. Photos can be submitted in any of the
following ways:
- Send digital photos to superconference@accessola.com (in any format but as high a resolution as possible).
- If you are a Flickr member, you may submit photos to the “Libraries of the World – OLA Super Conference Pool” Flickr group.Again, as high a resolution as possible.
- Send print photos to OLA, 50 Wellington St. East, Suite 201, Toronto M5E 1C8. Photos can be picked up at Super Conference from the Information Desk in the Registration Lobby. Any photos not picked up will be mailed to their owners following Super Conference.
Wednesday, January 02, 2008
Books that scientists use - an addendum

Some years ago when I started my tenure as Science Librarian at the Leddy Library, I worked on a particularly tedious project that really helped me get a better understanding on what books scientists actually use in their work (as opposed to so many other titles).
Using Web of Science, I would search for a year's worth of articles from Science, Nature and PNAS, download these articles' references into an Excel spreadsheet and try to decipher which ones were books. It was a very very mechanical and time-consuming process. But it made me a better science librarian.
Now, I'm pleased to say, that Scopus makes this same task possible in less than 30 seconds:
1. in search for box type in journal name (e.g. Nature) and select Source Title from drop-down menu
2. limit date range to a particular time period (e.g. 2007)
3. hit search button
4. in the Refine Results box, limit your results to just the journal name in question (e.g. Nature and not Nature Biochemistry)
5. in the Results box, click the Select All box and the hit the References button
6. If your initial search results brought more than 2000 hits, you will be informed that only the first 2000 articles will have their references retrieved.
7. review the list of most cited references of that journal from most cited to least
Here's a list of the 10 most cited books by Nature, Science, and PNAS*. The second number in the list represents where in the journal's list of most cited items can the book be found.
Most Cited Books in Nature, 2007**
1. [1] Molecular cloning: a laboratory manual (1989)
2. [2] Diagnostic Statistical Manual of Mental Disorders (1994)
3. [3] Numerical Recipes (1992)
4. [4] Biometry (1995)
5. [5] Biostastical Analysis (1984)
6. [7] The Rat Brain in Stereotaxic Coordinates (1986)
7. [13] Principles of Optics (1980)
8. [15] Physics of Semiconductor Devices (1981)
9. [19] Intermolecular and Surface Forces (1992)
10. [21] Co-Planar Stereotaxic Atlas of the Human Brain (1988)
Most Cited Books in Science, 2007**
1. [1] Diagnostic Statistical Manual of Mental Disorders (1994)
2. [2] CRC Handbook of Chemistry and Physics (2005)
3. [3] Biometry (1995)
4. [4] Biostastical Analysis (1984)
5. [5] The Rat Brain in Stereotaxic Coordinates (1986)
6. [9] Principles of Optics (1980)
7. [10] Computer Simulation of Liquids (1987)
8. [11] Structured Clinical Interview for DSM-III-R (1990)
9. [12] Advanced Organic Chemistry (1988)
10. [14] An Introduction to Probability Theory and its Applications (1971)
Most Cited Books in PNAS, 2007**
1. [1] Molecular cloning: a laboratory manual (1989)
2. [4] Diagnostic Statistical Manual of Mental Disorders (1994)
3. [6] Numerical Recipes (1992)
4. [8] CRC Handbook of Chemistry and Physics (2005)
5. [9] Biometry (1995)
6. [10] Biostatistical Analysis (1984)
7. [12] The Rat Brain in Stereotaxic Coordinates (1986)
8. [13] Handbook of Mathematical Functions (1972)
9. [22] Stastical Power Analysis for the Behavioral Sciences (1988)
10. [23] Statistical Methods (1980)
*Nature and Science published almost 2000 items in 2007 and PNAS published closer to 3000 items in 2007.
I'm planning to use this method to determine if there are any important books my library is missing by reviewing the references of the key journals in various fields for 2007. Its still a largely mechanical process (although the Foxy Leddy LibX toolbar makes book-checking much faster than typing titles into the library catalogue) but its a good task to slowly start the work of the new year.
**Addendum:
I've been thinking further about these lists and I think I am in grievous error.
For example: the approximately 2000 articles in Nature evidently produce 24,660 references. That's about 200 items in each item's bibliography - which sounds high but its in the realm of possibility. But what confuses me is the cited by column which says that the first item in the list, Molecular Cloning: A Laboratory Manual, has been cited 103, 825 times. So that must refer to how many times the item has been cited within the Scopus database. The fact that the some of the books in the list appear in the same relative order when performing the same procedure using the journals PNAS and Science, means that these lists reflect the most popular science books within Scopus and not necessarily within each journal.
Rats.
Subscribe to:
Posts (Atom)