I have never played this game but I can't wait for my children to get to the age in which I can try it out with them:
The game is called Shadows and it's a very simple role playing game that even very young children can play. In Shadows, the game master is the narrator of a story. The story begins with the characters waking up somewhere from a noise. The game master will then begin a story and occasionally interrupt it to ask those who are playing to do three things: say what they want to happen next; say what "Their Shadow" - a character that always wants to get into trouble - wants to happen next; and to roll two die. If the Shadow die comes up with a higher number than the "Good" die, then the story will unfold as The Shadow wants. [LionKimbro's unalog]
I have never played role playing games myself, but my friends and I in high school and in university, used to write "add-on short stories" (otherwise known as the Surrealist game, Exquisite Corpse) via email. Looking back at them, I would say that the characters we constructed were all Shadows of our own selves.
What detractors of games in libraries may not understand (or may care not to understand as is more often the case) is that gaming can be thought of as something much larger than following a set of rules to determine a winner and a loser. I'm following the work of Jane McGonigal trying to better understand what this much larger force is and can be.
Thursday, July 31, 2008
Tuesday, July 29, 2008
Newspapers as scaffolding for local stories
When I was cobbling together my information for my last post about the current drama about my local public library system, I had to resort to sources other than my local newspaper. This is because The Windsor Star puts all its articles older than 30 days old behind a paywall. And so in order to link to background information to provided better context to what I was describing, I had to resort to these articles unofficially reprinted online elsewhere and to local blogger commentary that wasn't exactly objective.
It made me realize something. Newspapers don't just describe events that become the historical record - they provide an important structure that supports discussion of those events. Now that The New York Times has made its archive available online, users can now link to articles to provide historical context to their online writings ("I'm so GenX that I still swing it on the flippity flop").
But smaller papers haven't made this leap of faith, and so our local memory is all short term. For example, today the mayor announced a plan to build a canal and marina in downtown Windsor (link will expire in time - a related problem). My husband told me that the local CBC news also reported this story and, unlike the Windsor Star, mentioned several other instances going back into the 1980s of similar failed plans for a marina downtown. I wasn't in Windsor in the 1980s and so this local knowledge was news to me.
There's another opportunity here. With a little bit of cataloguing and perhaps some semantic linking like Harper's Magazine has done, a newspaper archive could slowly evolve into its own reference work. Maybe an arrangement could be made. Libraries could trade staff time and cataloguing expertise in exchange for making the archives available for free to the public.
There has been discussion as of late whether Google (aka The Internet) is making us stupid. Maybe that's so, but by not putting our stories about local events on the Internet, we are in danger of being perpetually ignorant.
It made me realize something. Newspapers don't just describe events that become the historical record - they provide an important structure that supports discussion of those events. Now that The New York Times has made its archive available online, users can now link to articles to provide historical context to their online writings ("I'm so GenX that I still swing it on the flippity flop").
But smaller papers haven't made this leap of faith, and so our local memory is all short term. For example, today the mayor announced a plan to build a canal and marina in downtown Windsor (link will expire in time - a related problem). My husband told me that the local CBC news also reported this story and, unlike the Windsor Star, mentioned several other instances going back into the 1980s of similar failed plans for a marina downtown. I wasn't in Windsor in the 1980s and so this local knowledge was news to me.
There's another opportunity here. With a little bit of cataloguing and perhaps some semantic linking like Harper's Magazine has done, a newspaper archive could slowly evolve into its own reference work. Maybe an arrangement could be made. Libraries could trade staff time and cataloguing expertise in exchange for making the archives available for free to the public.
There has been discussion as of late whether Google (aka The Internet) is making us stupid. Maybe that's so, but by not putting our stories about local events on the Internet, we are in danger of being perpetually ignorant.
Monday, July 28, 2008
The City Council, The Windsor Public Library Board and The CEO
The CEO of The Windsor Public Library is today's front page news after some investigative journalism has revealed that Brian Bell has been articling at a local law firm while on sick leave from his library administrative duties. According to Bell, there is no malfeasance because working at a law firm is as relaxing as pottery lessons.
The WPL has been embroiled in this sort of drama for some years now. Here's the context as I understand it.
City councils in Ontario do not have the authority to make management decisions regarding libraries because of laws designed to protect library collection decisions from political influence. The Windsor Public Library is accountable to its Library Board. And yet its safe to say that The City of Windsor have been trying to gain control of The Windsor Public Library Board. Here's the evidence:
In March of this year, Windsor City Council requested a "line by line" financial audit of the WPL despite the fact that a similar audit performed two years ago found that the library system was running efficiently. Why so many audits? "Under provincial legislation, the only way council can take over [a library board] is if there has been mismanagement, and that's the driving force behind the financial request". Also in March, Council requested that the library cut its budget by $400,000 while stipulating that there would be no reduction in hours or services. Furthermore, in May, the City tried to prematurely end the terms of the WPL Library Board members.
Complicating matters it is no secret that the mayor of Windsor and his allies in Council are not fond of Alan Halberstadt who is the only remaining city councilor on the library board. In fact, they had the knives out for him after he did not side with City Council's recommendation for such large budget cuts (addendum) and again after it was learned that the Board mistakenly applied an Pay Equity payment to "funny how the former director of Human Resources could make such a mistake" Brian Bell. As an aside, I have a tremendous respect for Alan Halberstadt and I feel that the call to remove him from the Board by some of his fellow city councillors was deeply hypocritical.
And something that might be completely irrelevant or just might be further complicating matters is that Brian Bell succeeded previous Library CEO, Steve Salmons, who may or may not be the "former librarian" referred to by local columnist Gord Henderson who is part of the Ontario government's Detroit River International Crossing team, which is, incidentally, currently battling a heated turf war with the City of Windsor's own plans for a crossing.
I'm not sure how this is all going to resolve as the WPL operates under the Carver Protocol, a commercial governance model which, according to City Councillor David Cassivi, "largely renders the library board impotent" as it vests all responsibility in the office of the library's chief executive officer.
The WPL has been embroiled in this sort of drama for some years now. Here's the context as I understand it.
City councils in Ontario do not have the authority to make management decisions regarding libraries because of laws designed to protect library collection decisions from political influence. The Windsor Public Library is accountable to its Library Board. And yet its safe to say that The City of Windsor have been trying to gain control of The Windsor Public Library Board. Here's the evidence:
In March of this year, Windsor City Council requested a "line by line" financial audit of the WPL despite the fact that a similar audit performed two years ago found that the library system was running efficiently. Why so many audits? "Under provincial legislation, the only way council can take over [a library board] is if there has been mismanagement, and that's the driving force behind the financial request". Also in March, Council requested that the library cut its budget by $400,000 while stipulating that there would be no reduction in hours or services. Furthermore, in May, the City tried to prematurely end the terms of the WPL Library Board members.
Complicating matters it is no secret that the mayor of Windsor and his allies in Council are not fond of Alan Halberstadt who is the only remaining city councilor on the library board. In fact, they had the knives out for him after he did not side with City Council's recommendation for such large budget cuts (addendum) and again after it was learned that the Board mistakenly applied an Pay Equity payment to "funny how the former director of Human Resources could make such a mistake" Brian Bell. As an aside, I have a tremendous respect for Alan Halberstadt and I feel that the call to remove him from the Board by some of his fellow city councillors was deeply hypocritical.
And something that might be completely irrelevant or just might be further complicating matters is that Brian Bell succeeded previous Library CEO, Steve Salmons, who may or may not be the "former librarian" referred to by local columnist Gord Henderson who is part of the Ontario government's Detroit River International Crossing team, which is, incidentally, currently battling a heated turf war with the City of Windsor's own plans for a crossing.
I'm not sure how this is all going to resolve as the WPL operates under the Carver Protocol, a commercial governance model which, according to City Councillor David Cassivi, "largely renders the library board impotent" as it vests all responsibility in the office of the library's chief executive officer.
Friday, July 25, 2008
Everything I Think I Know About Designing Library Websites
Summertime is usually a quiet time in an academic library – except when during the year in which it’s been deemed that the library website needs a major overhaul. Then there is a team of library staff frantically hacking away as the September deadline lurches closer and closer.
I have been involved in such three library web redesign projects at MPOW over the years and have been meaning to write down some of the things that I think I have learned from the work before it becomes irrelevant. I want to qualify these statements as things I think I know because I can’t back up these statements with proper user testing. I am a huge advocate of re-iterative user testing but that’s not something that the web teams that I have belonged to have done enough of. I once received an email from a librarian who asked me what was the process by which our web team came up with the final design. I told her that we had frequent meetings and we argued a lot. She didn’t write me back. So much for honesty.
Since most academic libraries are more alike than different – they all tend to do the same things but just at different scales – it’s not surprising that most academic library websites tend to resemble each other. We are all trying to ‘solve’ the same problems and so it should not be surprising that we come up with similar solutions. I’ve come to believe that there are only a small number of academic library website archetypes that result from the answers to some simple questions.
How Do We Fit Everything We Do On the Front Page?
Libraries do lots of things and, in general, they want all of the things that they do represented somewhere on the library’s front page (along with a sizable real estate dedicated to ‘library news’). If you want all your offerings represented on the front page, you have one of two choices: you have drop down or fly-out menus or you create categories where each service goes. If you opt for drop-down menus, the site tends to be made up of two or three columns of the most important text with the less important stuff in the menus. If you don't want these menus, then your site tends to run to four or five columns of text broken down into categories such as 'services' and 'resources'.
At MPOW, we also did something slightly different. We knew that we were restrained to two columns of text because of the web template of our university but we didn’t want to use drop-down or flyaway menus. So instead, we developed a philosophy that the main body of text on our website would be dedicated to services that we could foresee a student or researcher use every day: the library catalogue, our indexes, online journals, citation management, interlibrary loan (which, in an ideal world, would appear as a link in an index or library catalogue when a failed search occurred), booking a library computer, and book renewal (which admittedly doesn’t exactly fit the criteria of daily). Most everything else is found in the groups “About the Library”, “Research Help”, “Computer Help”, and “Writing Help”. The benefit of using this approach is that you are less likely to screw up the major deliverables that your website is supposed to provide. But there is a cost – some things do become lost.
The Search for Search
When we designed our library’s website, we thought that our sitemap would be the answer to the problem of our hidden content. But since then I have come to realize that the average user doesn’t look for a site map and have noticed that site maps are now becoming scarce in the rest of the online world. We have a link to a ‘search this site’ page but even though it has prime real estate on the front page – it is rarely used. Why? My hunch is that is that if users don’t see a search box on a web page, they will assume that no search function exists and won’t look elsewhere on the page for this. At the time of the re-design, we didn’t want to put a search box on our front page because we knew from experience that user will gravitate to it and automatically search what are looking for (title of a book, journal article, journal name, library hours) completely undaunted by whatever the search box is labeled.
Beyond The Question of Language
And yet we know that the choice of words is very important to the success of a web site. I think it’s now commonly understood that users will understand ‘books’ more than ‘library catalogue’ and understand either of those terms much more than a brand name such as ‘Infobridge’ or ‘Voyager’. What still not been excised from our way of thinking about academic library web sites is the word and the notion of ‘database’. As librarians, we tend to think of ourselves as a database supplier for our users. But the word ‘database’ means nothing to students. The same goes for the words ‘Resources’ or ‘E-Resources’. That’s because in the rest of our users’ online experiences, they are never asked to visit different ‘databases’ of a particular site. The solution is not just to find other words that make more sense (we use ‘Research Tools’) but to create a web experience in which the parts of a library’s online services come together as an integrated whole to make such labels unnecessary. I’m also hoping that our future academic website will resemble the non-scholarly world and present customized services and information about services through an ‘Account’ section.
An Aside
One of the reasons why I write is because I find it’s a helpful exercise for me to clear the fog and figure out what I know and what I don’t know. And as I have been writing this, I have again come to the realization that I don’t know as much as I thought when I started putting fingers to keyboard. That’s as good as a conclusion I can make at the moment : I think it’s a useful exercise for academic libraries to figure out and articulate what we know and what we don’t know about academic library web design. There’s so much to being honest.
I have been involved in such three library web redesign projects at MPOW over the years and have been meaning to write down some of the things that I think I have learned from the work before it becomes irrelevant. I want to qualify these statements as things I think I know because I can’t back up these statements with proper user testing. I am a huge advocate of re-iterative user testing but that’s not something that the web teams that I have belonged to have done enough of. I once received an email from a librarian who asked me what was the process by which our web team came up with the final design. I told her that we had frequent meetings and we argued a lot. She didn’t write me back. So much for honesty.
Since most academic libraries are more alike than different – they all tend to do the same things but just at different scales – it’s not surprising that most academic library websites tend to resemble each other. We are all trying to ‘solve’ the same problems and so it should not be surprising that we come up with similar solutions. I’ve come to believe that there are only a small number of academic library website archetypes that result from the answers to some simple questions.
How Do We Fit Everything We Do On the Front Page?
Libraries do lots of things and, in general, they want all of the things that they do represented somewhere on the library’s front page (along with a sizable real estate dedicated to ‘library news’). If you want all your offerings represented on the front page, you have one of two choices: you have drop down or fly-out menus or you create categories where each service goes. If you opt for drop-down menus, the site tends to be made up of two or three columns of the most important text with the less important stuff in the menus. If you don't want these menus, then your site tends to run to four or five columns of text broken down into categories such as 'services' and 'resources'.
At MPOW, we also did something slightly different. We knew that we were restrained to two columns of text because of the web template of our university but we didn’t want to use drop-down or flyaway menus. So instead, we developed a philosophy that the main body of text on our website would be dedicated to services that we could foresee a student or researcher use every day: the library catalogue, our indexes, online journals, citation management, interlibrary loan (which, in an ideal world, would appear as a link in an index or library catalogue when a failed search occurred), booking a library computer, and book renewal (which admittedly doesn’t exactly fit the criteria of daily). Most everything else is found in the groups “About the Library”, “Research Help”, “Computer Help”, and “Writing Help”. The benefit of using this approach is that you are less likely to screw up the major deliverables that your website is supposed to provide. But there is a cost – some things do become lost.
The Search for Search
When we designed our library’s website, we thought that our sitemap would be the answer to the problem of our hidden content. But since then I have come to realize that the average user doesn’t look for a site map and have noticed that site maps are now becoming scarce in the rest of the online world. We have a link to a ‘search this site’ page but even though it has prime real estate on the front page – it is rarely used. Why? My hunch is that is that if users don’t see a search box on a web page, they will assume that no search function exists and won’t look elsewhere on the page for this. At the time of the re-design, we didn’t want to put a search box on our front page because we knew from experience that user will gravitate to it and automatically search what are looking for (title of a book, journal article, journal name, library hours) completely undaunted by whatever the search box is labeled.
Beyond The Question of Language
And yet we know that the choice of words is very important to the success of a web site. I think it’s now commonly understood that users will understand ‘books’ more than ‘library catalogue’ and understand either of those terms much more than a brand name such as ‘Infobridge’ or ‘Voyager’. What still not been excised from our way of thinking about academic library web sites is the word and the notion of ‘database’. As librarians, we tend to think of ourselves as a database supplier for our users. But the word ‘database’ means nothing to students. The same goes for the words ‘Resources’ or ‘E-Resources’. That’s because in the rest of our users’ online experiences, they are never asked to visit different ‘databases’ of a particular site. The solution is not just to find other words that make more sense (we use ‘Research Tools’) but to create a web experience in which the parts of a library’s online services come together as an integrated whole to make such labels unnecessary. I’m also hoping that our future academic website will resemble the non-scholarly world and present customized services and information about services through an ‘Account’ section.
An Aside
One of the reasons why I write is because I find it’s a helpful exercise for me to clear the fog and figure out what I know and what I don’t know. And as I have been writing this, I have again come to the realization that I don’t know as much as I thought when I started putting fingers to keyboard. That’s as good as a conclusion I can make at the moment : I think it’s a useful exercise for academic libraries to figure out and articulate what we know and what we don’t know about academic library web design. There’s so much to being honest.
Wednesday, July 23, 2008
One reason books are beautiful - less diapers to worry about
OK, I am fully aware how silly this story will sound but parenting is serious business dammit.
The day after my son first read his new book Uh-Oh Gotta Go by Bob From Sesame Street he started using the potty on a consistent basis.
Its pretty incredible, when you think about it, that a simple picture book depicting happy toddlers using the potty can inspire a real two year old to do the same.
The day after my son first read his new book Uh-Oh Gotta Go by Bob From Sesame Street he started using the potty on a consistent basis.
Its pretty incredible, when you think about it, that a simple picture book depicting happy toddlers using the potty can inspire a real two year old to do the same.
Monday, July 21, 2008
Sunday, July 20, 2008
Using Google and FriendFeed to Create a Collaborative Research Environment
Some months ago, I suggested that one way to measure of a success of a library's discovery system is to compare it to Google. I've been thinking about extending this measuring stick to the rest of the support that libraries provide to their researchers. So, I created a Google account for a fictional Cloud Researcher.
After creating a Gmail account for "Cloud Researcher" I started a Google Reader account for her. It was shockingly easy to add an RSS feed of the most recent issues to the more well known journals such as Nature and Science. Now my researcher can stay up to date in her field.
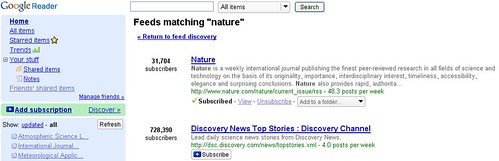
Google Reader makes it easy to share items by allowing instant publishing to a clippings blog. (This feature will prove important later on)

I then created a customized Google search engine so whenever my researcher needs to refer or research, she can just search this index of just the journals and websites that she trusts. If she wants to cast a wider net, she can always opt to search with Google Scholar or even plain old vanilla Google.
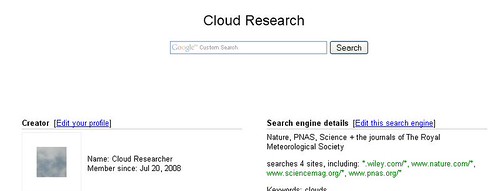
If her affiliated academic library provides authentication by IP address, then our researcher can keep up with her journal reading on campus without ever visiting the library's website even once - even if she's off-campus by using Windows XP Remote Desktop option to access her work computer. And if she has a loving, caring library, she can authenticate and access research using LibX, which also comes in handy when she uses Google Books.
I'm glad I actually went through the exercise of actualizing this example because in doing so, I had a small epiphany which was this: the future of learning online space is going to be an aggregation of online services. I realized this when I started playing with FriendFeed.
I've been using FriendFeed for about a week now and I still find it a strange beast. The way I would describe it is FriendFeed = Twitter + RSS reader. I think FF is an improvement on Twitter because it allows others to comment directly to a post. But FF is not a conventional RSS reader like Bloglines or Google Reader as the emphasis is on following friends - not publications. But what you can do with FriendFeed is create different 'rooms' for your different circle of friends. I created a room called The Cloud Research Lab Room.
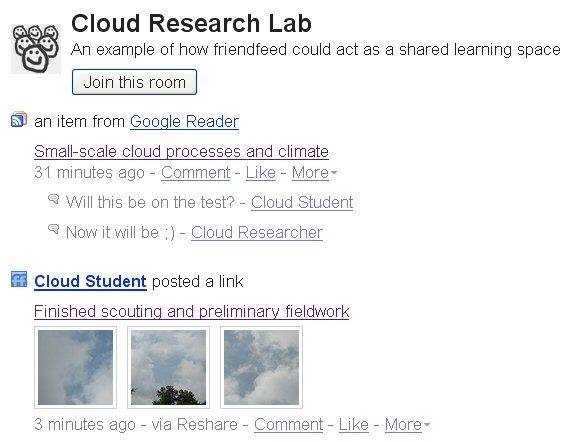
What would happen if FriendFeed could share structured bibliographic citations from Zotero?
I think it could be something wonderful.
After creating a Gmail account for "Cloud Researcher" I started a Google Reader account for her. It was shockingly easy to add an RSS feed of the most recent issues to the more well known journals such as Nature and Science. Now my researcher can stay up to date in her field.
Google Reader makes it easy to share items by allowing instant publishing to a clippings blog. (This feature will prove important later on)
I then created a customized Google search engine so whenever my researcher needs to refer or research, she can just search this index of just the journals and websites that she trusts. If she wants to cast a wider net, she can always opt to search with Google Scholar or even plain old vanilla Google.
If her affiliated academic library provides authentication by IP address, then our researcher can keep up with her journal reading on campus without ever visiting the library's website even once - even if she's off-campus by using Windows XP Remote Desktop option to access her work computer. And if she has a loving, caring library, she can authenticate and access research using LibX, which also comes in handy when she uses Google Books.
I'm glad I actually went through the exercise of actualizing this example because in doing so, I had a small epiphany which was this: the future of learning online space is going to be an aggregation of online services. I realized this when I started playing with FriendFeed.
I've been using FriendFeed for about a week now and I still find it a strange beast. The way I would describe it is FriendFeed = Twitter + RSS reader. I think FF is an improvement on Twitter because it allows others to comment directly to a post. But FF is not a conventional RSS reader like Bloglines or Google Reader as the emphasis is on following friends - not publications. But what you can do with FriendFeed is create different 'rooms' for your different circle of friends. I created a room called The Cloud Research Lab Room.
What would happen if FriendFeed could share structured bibliographic citations from Zotero?
I think it could be something wonderful.
Friday, July 18, 2008
Library Labyrinth
Perhaps it was my recent visit to IKEA or perhaps its from my daily lurking of Find The Lost Ring ARG (which is dedicated to the lost sport of Labyrinth Running), but I keep thinking that there should be a library that contains bookshelves organized so that they create a labyrinth path.
The meandering but purposeful path of the labyrinth is a metaphor for life. Unlike a maze, there is only one path in and out. There are no shortcuts, no dead ends, and the entire path must be followed to complete the journey. The labyrinth visually reminds us that we are walking a common path. Often circular in design, they represent wholeness and unity. Interest in the labyrinth as a tool for relaxation, healing, building community, solving problems, and nurturing intuition, creativity, and artistic expression has increased significantly over the past several years. They can be found in hospitals, parks, schools, prisons, retreat centers, faith- based organizations, and private gardens. [the library as labyrinth]
Thursday, July 10, 2008
Z for Zotero!
I've been holding out from using Zotero but I think I will be making the switch as soon as these features come out of beta:
I'm also particularly intrigued how Zotero and others will take advantage of RDF and the Semantic Web now that a Bibliographic Ontology has been established.
- synchronization of work from different computer browsers
- adoption of Endnote citation styles
- communication with the Internet Archive
- zeroconf!
I'm also particularly intrigued how Zotero and others will take advantage of RDF and the Semantic Web now that a Bibliographic Ontology has been established.
Subscribe to:
Comments (Atom)